Искусственные нейронные сети и их применение на рынке Форекс. Нейросеть для биржи
Использование нейросети в торговле на Форекс и биржах
Искусственная нейронная сеть представляет собой математическую модель, воплощенную в виде компьютерной программы и имитирующую работу центральной нервной системы живых организмов.
Что такое Нейронная сеть
Понятие «Нейронная сеть» (НС) появилось в ходе изучения процессов, идущих в головном мозге, и попыток их воспроизведения. В настоящее время разработано множество алгоритмов, которые нашли применение во многих областях, где требуется анализ, распознавание и прогнозирование, включая нейросеть для торговли на бирже.
Нейронные сети в торговле на биржах – это системы анализа данных, которые, в отличие от обычных программ, работают не сугубо в рамках прописанного набора действий, а самообучаются в процессе работы благодаря возможностям машинного обучения и тестирования различных исходов и ситуаций на основе прошлых событий. В ходе обучения НС выявляет сложные взаимосвязи, которые непросто рассмотреть в обычных обстоятельствах.
Современные торговые советники и роботы опираются только на один алгоритм и не способны самообучаться. Поэтому при смене рыночной ситуации приходится останавливать работу советника или перенастраивать его алгоритм. Даже в процессе работы советника, он может выдавать много ложных сделок, так как рыночная ситуация может не соответствовать его заданному алгоритму.
Нейросети на Форекс позволят избежать подобных ситуаций. Вернее, предполагается, что позволят. На данный момент сделаны лишь первые шаги в этом направлении. О создании полноценной аналитической системы, которая могла бы самостоятельно переключаться и определять рыночные состояния, а также принимать решения исходя из этого, говорить пока что не приходится.
Что такое нейросети на Форекс
 В последние время трейдерское сообщество все чаще обсуждает машинное обучение и нейросети на Форекс и бирже. Эта тема не совсем нова: в докризисные годы были популярны торговые программы на базе НС NeuroSolutions и NeuroShell. Сейчас, после внедрения Google и Microsoft этой технологии в свои переводчики и голосовой поиск, продвинутые трейдеры снова обратили на нее внимание.
В последние время трейдерское сообщество все чаще обсуждает машинное обучение и нейросети на Форекс и бирже. Эта тема не совсем нова: в докризисные годы были популярны торговые программы на базе НС NeuroSolutions и NeuroShell. Сейчас, после внедрения Google и Microsoft этой технологии в свои переводчики и голосовой поиск, продвинутые трейдеры снова обратили на нее внимание.
Нейросеть простыми словами – это система, имитирующая работу головного мозга, способная к обучаться и приспосабливаться к меняющимся условиям, а также прогнозировать ситуации. Применительно к торговле на финансовых рынках это означает, что для анализа можно использовать не только котировки, как в случае торговых роботов, но и любые другие данные, которые пользователь сочтет нужными. Кроме того, всю исходную информацию можно комбинировать в любых пропорциях.
Однако нейросети на Форекс все еще недоступны для широких масс трейдеров. Поэтому большинству приходится пока что изучать их работу в теории.
Главной трудностью применения искусственных нейросетей является процесс их обучения. Другим препятствием становится высокая стоимость нейропакетов и в особенности специального оборудования для них – нейрокомпьютеров.
Посмотрите короткое видео о использовании нейросетей в торговле на биржах:
Некоторые американские компании как LBS Capital Management Inc. покупают небольшие нейропакеты и нейрокомпьютеры до $50000 и улучшают свои торговые показатели на американских фондовых индексах S&P 500 или Nasdaq 100.
Схема работы нейронной сети:

Задачи для нейросети
Выборка статистики в качестве обучающего элемента имеет для НС решающее значение. Состав данных может быть очень широким, однако встает вопрос отсеивания ненужной информации. Справиться с фильтрацией входных данных для нейронного советника можно, используя несколько способов.
- Большинство нейропакетов включают опцию определения чувствительности к входной информации. Эта функция позволяет загружать все имеющиеся данные без сортировки, после чего сеть сама покажет, какие данные более приоритетны. Ввиду непрогнозируемости времени обучения НС этот способ далек от оптимального, однако является самым простым.
- Данные проверяются на противоречивость: большое количество взаимоисключающей информации способно полностью блокировать возможность получения сколько-нибудь точного рыночного прогноза.
- Возможно использование нейросетевых программных инструментов, работающих по технологии Data Maining. В основе такого метода обработки информации лежит классификация данных различными способами, включая нечеткую логику.
- Применяются методы корреляционного и кластерного анализа, а также исследование временных рядов, которые дают возможность группировки введенных данных. Также они выявляют отношение числовых показателей друг к другу и их цикличность применительно к отдельным элементам и к группам цифр.
Почему нейронные сети не применяются активно в трейдинге?
Существует несколько довольно простых и нетривиальных объяснений отсутствию популярности таких технологий в современном трейдинге среди широкой массы частных инвесторов. Связано это как с дороговизной подобных пакетов, так и с необходимостью последующего обучения сети.
То есть готовых решений нет. Вам придется все равно заниматься настройками и подготовкой подобных алгоритмов вручную. Кстати для этого потребуются знания в той области, в которой будут применяться нейросети. А ведь многие трейдеры хотят получить в свои руки готовый инструмент, который не требует никаких доработок и, главное, усилий.
В самой популярной торговой платформе для рынка Форекс – MetaTrader пока что нет возможности подключения модулей для нейросетей, хотя попытки уже предпринимались и уже написаны некоторые готовые библиотеки. Сейчас есть возможность подключения программ машинного обучения у платформы Wealth Lab, но программирование данных модулей – задача очень сложная и на данный момент не реализованная.
Еще одна причина связана с тем, что нейросети в целом пока что не пользуются высоким спросом и в других областях.
Полезные статьи:
В каких сферах успешно применяются нейронные сети
Наверняка среди читателей довольно много скептиков в отношении применения подобных технологий в трейдинге, да и в любой другой сфере. Поэтому сейчас мы расскажем о том, где нейронные сети уже применяются, причем довольно успешно.
В Великобритании ученые внедрили такую технологию в медицину для оценки рисков сердечно-сосудистых заболеваний. Причем алгоритмы прошли «обучение» на данных от более чем 300 000 пациентов. В результате, искусственный интеллект оказался даже эффективнее, чем человек.
Используются такие сети и в сфере финансов. В частности, в Японии одна из страховых компаний внедрила специальный алгоритм, который будет изучать медицинские сертификаты и историю болезней, а также перенесенных операций для расчета условий страхования клиентов.
Нейросети успешно применяются сегодня в поисковых алгоритмах Яндекс и Google. Помимо этого, они используются, к примеру, в Amazon. В известнейшей интернет-сети продаж благодаря автоматизации механизма рекомендаций осуществляется 35% продаж.
В будущем ожидается, что такие алгоритмы смогут использоваться и для работы так называемых чат ботов и смогут заменить сотрудников Call-центров.
Применяются нейронные сети и на транспорте. В частности, речь идет о беспилотных автомобилях и других разработках в этой отрасли, которые ведутся известными компаниями Google, Yandex, Uber.
Наконец, внедрение искусственного интеллекта наблюдается также в промышленном производстве и сельском хозяйстве.
Плюсы и минусы
А теперь разберемся с преимуществами и недостатками применения нейронных сетей в торговле на бирже.
 Одним из главных является то, что системы такого рода постоянно обучаются. Появляются новые данные и нейросети учитывают их в процессе анализа.
Одним из главных является то, что системы такого рода постоянно обучаются. Появляются новые данные и нейросети учитывают их в процессе анализа.
Второй важный момент – современные системы такого рода могут комбинировать технические и фундаментальные данные. Соответственно, применять подобную методику можно для прогнозирования, к примеру, по системе Прайс экшн и, при этом, исключить влияние фундаментальных факторов на результаты торговли.
Что касается недостатков, они также присутствуют. К ним можно отнести, к примеру, то, что если на входе подавались неверные данные, то и результат будет соответствующим.
Наконец, из доступных сегодня систем, построенных на базе нейронных сетей, большинство показывает точность прогнозов в 50-60%. То есть данные методики пока что не отличаются высокой точностью.
Именно по этой причине многие трейдеры полагают, что нейронные сети вообще не работают и их использование в трейдинге бесперспективно. В некотором плане с ними можно согласиться, так как на современном этапе точность таких прогнозов очень низка. Поэтому смысла в них нет никакого. Но в будущем, ситуация может улучшиться.
В любом случае, применение нейронных сетей никогда не отменит необходимость наличия знаний в области трейдинга. Для того, чтобы обучить такую технологию, необходимо понимать как и зачем, а главное чему обучать искусственный интеллект. Даже если и будут готовые решения, они вряд ли полностью заменят трейдера.
Заключение
В статье мы рассказали о том, что такое нейросети и как они применяются на практике в различных сферах. Как видите, в торговле на биржах нейросети сегодня практически не используются, равно как и в трейдинге на Форекс. Однако в будущем ситуация может кардинально поменяться.
Если вы нашли ошибку, пожалуйста, выделите фрагмент текста и нажмите Ctrl+Enter, и мы её обязательно исправим! Огромное спасибо вам за помощь, это очень важно для нас и других читателей!

investingnotes.trade
10 заблуждений о нейронных сетях / Блог компании ITI Capital / Хабр

Нейронные сети – один из самых популярных классов алгоритмов для машинного обучения. В финансовом анализе они чаще всего применяются для прогнозирования, создания собственных индикаторов, алгоритмического трейдинга и моделирования рисков. Несмотря на все это, репутация у нейронных сетей подпорчена, поскольку результаты их применения можно назвать нестабильными.
Количественный аналитик хедж-фонда NMRQL Стюарт Рид в статье на сайте TuringFinance попытался объяснить, что это означает, и доказать, что все проблемы кроются в неадекватном понимании того, как такие системы работают. Мы представляем вашему вниманию адаптированный перевод его статьи.
1. Нейронная сеть – это не модель человеческого мозга
Человеческий мозг – одна из самых больших загадок, над которой бьются ученые не одно столетие. До сих пор нет единого понимания, как все это функционирует. Есть две основные теории: теория о «клетке бабушки» и теория дистрибутивного представительства. Первая утверждает, что отдельные нейроны имеют высокую информационную вместимость и способны формировать сложные концепты. Например, образ вашей бабушки или Дженнифер Энистон. Вторая говорит о том, что нейроны намного проще в своем устройстве и представляют комплексные объекты лишь в группе. Искусственную нейронную сеть можно в общих чертах представить как развитие идей второй модели.Огромная разница ИНС от человеческого мозга, помимо очевидной сложности самих нейронов, в размерах и организации. Нейронов и синапсов в мозгу несоизмеримо больше, они самостоятельно организуются и способны к адаптации. ИНС конструируют как архитектуру. Ни о какой самоорганизации в обычном понимании не может быть речи.
Что из этого следует? ИНС создаются по архетипу человеческого мозга в том же смысле, как олимпийский стадион в Пекине был собран по модели птичьего гнезда. Это ведь не означает, что стадион – это гнездо. Это значит, что в нем есть некоторые элементы его конструкции. Лучше говорить о сходстве, а не совпадении структуры и дизайна.
Нейронные сети, скорее, имеют отношение к статистическим методам – соответствия кривой и регрессии. В контексте количественных методов в финансовой сфере заявка на то, что нечто работает по принципам человеческого мозга, может ввести в заблуждение. А в неподготовленных умах вызвать страх угрозы вторжения роботов и прочую фантастику.
Пример кривой, также известной как функция приближения. Нейронные сети очень часто используют для аппроксимации сложных математических функций
2. Нейронная сеть – не упрощенная форма статистики
Нейронные сети состоят из слоев соединенных между собой узлов. Отдельные узлы называются перцептронами и напоминают множественную линейную регрессию. Разница в том, что перцептроны упаковывают сигнал, произведенный множественной линейной регрессией, в функцию активации, которая может быть как линейной, так и нелинейной. В системе со множеством слоев перцептронов (MLP) перцептроны организованы в слои, которые в свою очередь соединены друг с другом. Есть три типа слоев: слои входных данных и выходных сигналов, скрытые слои. Первый слой получает паттерны входных данных, второй может поддерживать список классификации или сигналы вывода в соответствии со схемой. Скрытые слои регулируют веса входных данных, пока риски ошибки не сводятся к минимуму.Картирование инпутов/аутпутов
Перцепторы получают векторы входных данных — z=(z1,z2,…,zn) из n атрибутов. Вектор называется входным паттерном (input pattern). Вес такого «инпута» определяется весом вектора, принадлежащего к этому перцептрону — v=(v1,v2,…,vn). В контексте множественной линейной регрессии это можно представить как коэффициент регрессии. Сигнал перцептрона в сети, net, обычно складывается из входного паттерна и его веса.net=∑nizivi Сигнал минус смещение θ затем преобразуется в некую активационную функцию. Обычно это монотонно возрастающая функция с границами (0,1) или (-1,1). Некоторые наиболее популярные функции представлены на картинке: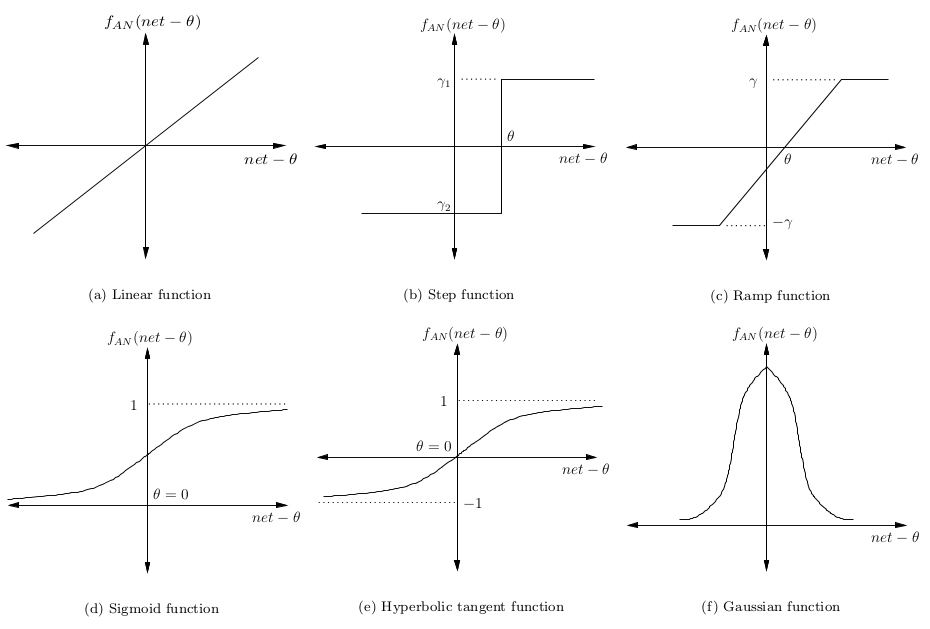
Простейшая нейронная сеть – так, которая имеет лишь один нейрон, картирующий входные сигналы в выходные.
Создание слоев
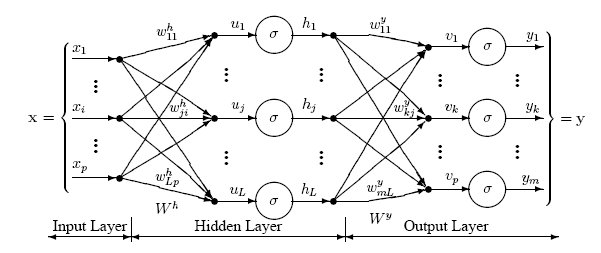
Как видно из рисунка, перцептроны организованы в слои. Первый слой, который позже получит название входного, получает паттерн p в процессе обучения – Pt. Последний слой привязан к ожидаемым выходным сигналам для этих паттернов. Паттерны могут быть величинами разных технических индикаторов, а потенциальные выходные сигналы могут быть категориями {BUY,HOLD,SELL}.
Скрытый слой – тот, который получает инпуты и аутпуты от другого слоя и формирует аутпуты для следующего. По одной из версий, скрытые слои извлекают выступающие элементы из входящих данных, которые имеют значение для предсказания результата. В статистике такая техника зовется первичным компонентным анализом.
Глубокая нейронная сеть имеет большое количество скрытых слоев и способна извлекать больше подходящих элементов данных. Недавно их с успехом использовали для решения проблем распознавания образов.
В задачах трейдинга при использовании глубоких сетей есть одна проблема: данные на входе уже подготовлены и может быть сразу несколько элементов, которые необходимо извлечь.
Правила обучения
Задача нейронной сети минимизировать степень ошибки ϵ. Обычно этот показатель рассчитывается как сумма квадратов ошибок. Хотя такой вариант может быть чувствителен к постороннему шуму.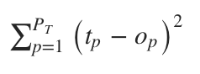
Для наших целей мы можем использовать алгоритм оптимизации, чтобы приспособить показатели веса к сети. Чаще всего для обучения сети применяют алгоритм градиентного спуска. Он работает через калькуляцию частичных дериватов ошибок с учетом их веса для каждого слоя и затем двигается в обратном направлении по уклону. Минимизируя ошибку, мы увеличиваем производительность сети в выборке.
Математически это правило обновления можно выразить в следующей формуле:
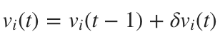 , где
, где 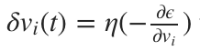 , где
, где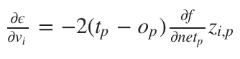
η – частота обучения, отвечающая за то, как быстро или медленно сеть конвергируется. Выбор частоты обучения имеет серьезные последствия в плане производительности нейронной сети. Маленькое значение приведет к медленной конвергенции, большое может привести к отклонениям в обучении.
Итак, нейронная сеть – это не есть упрощенная форма статистики для ленивых аналитиков. Это некая выдержка серьезных статистических методов, применяемых уже сотни лет.
3. Нейронная сеть может быть исполнена в разной архитектуре
До этого момента мы рассуждали о самой примитивной архитектуре нейронной сети – системе многоуровневых перцептронов. Есть еще множество вариантов, от которых зависит производительность. Современные достижения в изучении машинного обучения связаны не только с тем, как работают оптимизационные алгоритмы, но как они взаимодействуют с перцептронами. Автор предлагает рассмотреть наиболее интересные, с его точки зрения, модели.Рекуррентная нейронная сеть: у нее некоторые или все соединения отыгрывают назад. По сути, это принцип технологии Feed Back Loop (уведомление провайдера сервису рассылки при наборе критического числа жалоб на спам). Считается, что такая сеть лучше работает на серийных данных. Если так, то этот вариант вполне уместен в отношении финансовых рынков. Для более подробного ознакомления нам предлагают почитать вот эту статью.
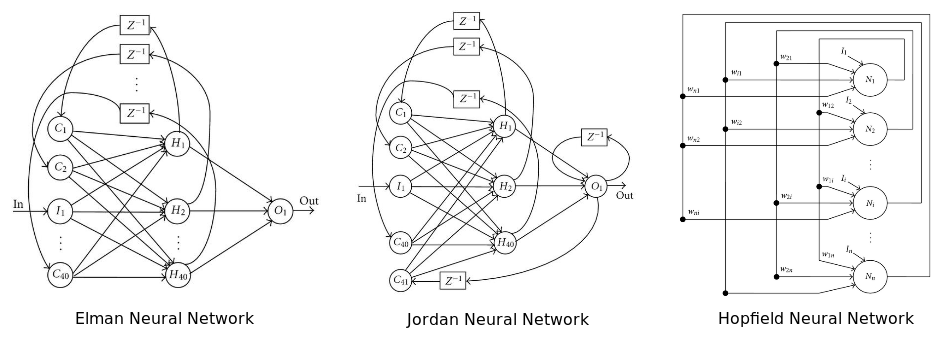
На диаграмме изображены три популярных архитектуры нейронных сетей
Последний из придуманных вариантов архитектуры рекуррентной нейронной сети – нейронная машина Тьюринга. Она объединяет архитектуру стандартной сети с памятью.
Нейронная сеть Больцмана – одна из первых полностью связанных нейронных сетей. Она одной из первых была способна обучаться внутренним представлениям и решать сложные задачи по комбинаторике. Про нее говорят, что это версия Монте-Карло рекуррентной нейронной сети Хопфилда. Ее сложнее обучать, но если поставлены ограничения, то она эффективней традиционной сети. Самое распространенное ограничение в отношении сети Больцмана – запрет на соединения между скрытыми нейронами. Собственно, еще один вариант архитектуры.
Глубокая нейронная сеть – сеть со множеством скрытых слоев. Такие сети стали крайне популярны в последние годы, из-за их способности с блеском решать проблемы по распознаванию голоса и изображения. Число архитектур в данном варианте растет небывалыми темпами. Самые популярные: глубокие сети доверия, сверточные нейронные сети, автокодировщики стэка и прочее. Самая главная проблема с глубокими сетями, особенно в случае с финансовым анализом, — переобучение.
Адаптивная нейронная сеть одновременно адаптирует и оптимизирует архитектуру в процессе обучения. Она может наращивать архитектуру (добавлять нейроны) или сжимать ее, убирая ненужные скрытые нейроны. По мнению автора, эта сеть лучше всего подходит для работы на финансовых рынках, потому что сами эти рынки не стационарны. То есть сеть способна подстраиваться под динамику рынка. Все, что было здорово вчера, не факт, что будет оптимально работать завтра.
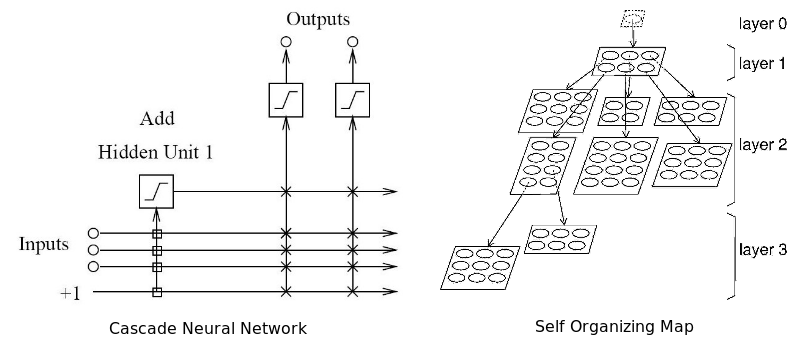
Два типа адаптивных нейронных сетей: каскадная и самоорганизующаяся карта
Радиально-базисная сеть – не то чтобы отдельный тип архитектуры в плане размещения соединений и перцептронов. Здесь в качестве активирующей функции используется радиально-базисная функция, чьи аутпуты зависят от расстояния от конкретной точки. Самое распространенное применение этой функции – гауссовское распределение. Она также используется как ядро в векторной машине поддержки.
Проще всего – попробовать несколько вариантов на практике и выбрать наиболее подходящий под конкретные задачи.
4. Размер имеет значение, но больше – не всегда значит лучше
После выбора архитектуры возникает вопрос, насколько большой или насколько небольшой должна быть нейронная сеть? Сколько должно быть «инпутов»? Сколько нужно использовать скрытых нейронов? Скрытых слоев (в случае с глубокой сетью)? Сколько «аутпутов» нужно нейронам? Если мы промахнемся с размером, сеть может пострадать от переобучения или недообучения. То есть не будет способна грамотно обобщать.Сколько и какие инпуты нужно использовать?
Число входных сигналов зависит от решаемой проблемы, количества и качества доступной информации и, возможно, некоторой доли креатива. Выходные сигналы – это простые переменные, на которые мы возлагаем некие предсказательные способности. Если входные данные к проблеме не ясны, можно определять переменные для включения через систематический поиск корреляций и кросс-корреляций между потенциальными независимыми переменными и зависимыми переменными. Этот подход детально рассматривается в этой статье.С использованием корреляций есть две основные проблемы. Во-первых, если вы используете метрику линейной корреляции, вы можете непреднамеренно исключить нужные переменные. Во-вторых, две относительно не коррелированных переменных могут быть потенциально объединены для получения одной хорошо коррелированной переменной. Когда вы смотрите на переменные изолировано, вы можете упустить эту возможность. Здесь можно использовать основной компонентный анализ для извлечения полезный векторов в качестве входных сигналов.
Другая проблема при выборе переменных – мультиколлинеарность. Это когда две или более переменных, загруженных в модель, имеют высокую корреляцию. В контексте регрессивных моделей это может вызвать хаотичные изменения регрессивного коэффициента в ответ на незначительные изменения в модели или в данных. Учитывая то, что нейронные сети и регрессионные модели схожи, можно предположить, что та же проблема распространяется на нейронные сети.
Еще один момент связан с тем, что за выбранные переменные принимают пропущенные отклонения в переменных. Они появляются, когда модель уже сформирована, а за бортом осталась парочка важных каузальных переменных. Отклонения проявляют себя, когда модель получает неверное возмещение отсутствующим переменным через переоценку или недооценку других переменных.
Сколько необходимо скрытых нейронов?
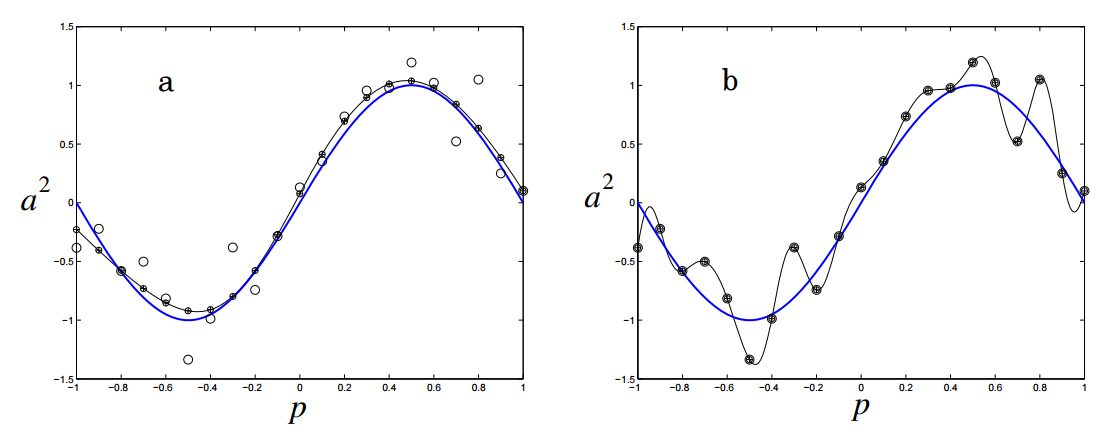
Оптимальное число скрытых элементов – специфическая проблема, решаемая опытным путем. Но общее правило: чем больше скрытых нейронов – тем выше риск переобучения. В этом случае система не изучает возможности данных, а как бы запоминает сами паттерны и любой содержащийся в них шум. Такая сеть отлично работает на выборке и плохо за пределами выборки. Как можно избежать переобучения? Есть два популярных метода: ранняя остановка и регуляризация. Автор предпочитает свой, связанный с глобальным поиском.Ранняя остановка предполагает разделение процесса обучения на этапы самого обучения и валидации результатов. Вместо того чтобы обучать сеть на ограниченном числе итераций, вы обучаете ее пока производительность сети на этапе подтверждения не начинает падать. По-существу, это не дает сети использовать все доступные параметры и ограничивает способности к простому запоминанию паттернов. Ниже показаны две возможные точки остановки:
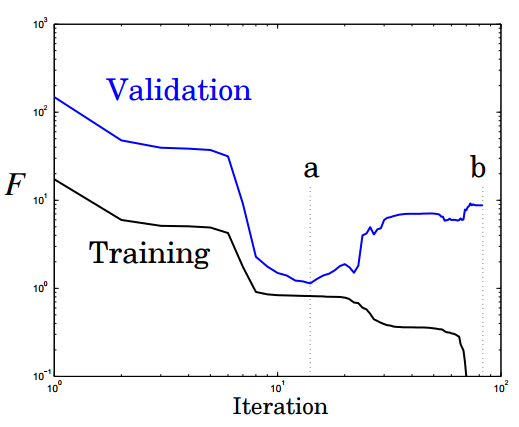
Еще одна картинка показывает производительность и степень переобучение сети при остановке в этих точках a и b:
Регуляризация штрафует нейронную сеть за использования усложненной архитектуры. Сложность в данном случае измеряется размером и весом сети. Она устанавливается через добавление интервала к функции ошибки, который привязан к весу и размеру. Это то же самое, что добавление приоритета, который заставляет поверить нейронную сеть функцию на однородность.
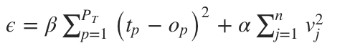
n- это число нагрузок (весов) в нейронной сети. Параметры α и β контролируют уровень, после которого наступает недообучение или переобучение сети. Подходящие значения для них можно подобрать через Байесовский анализ и оптимизацию.
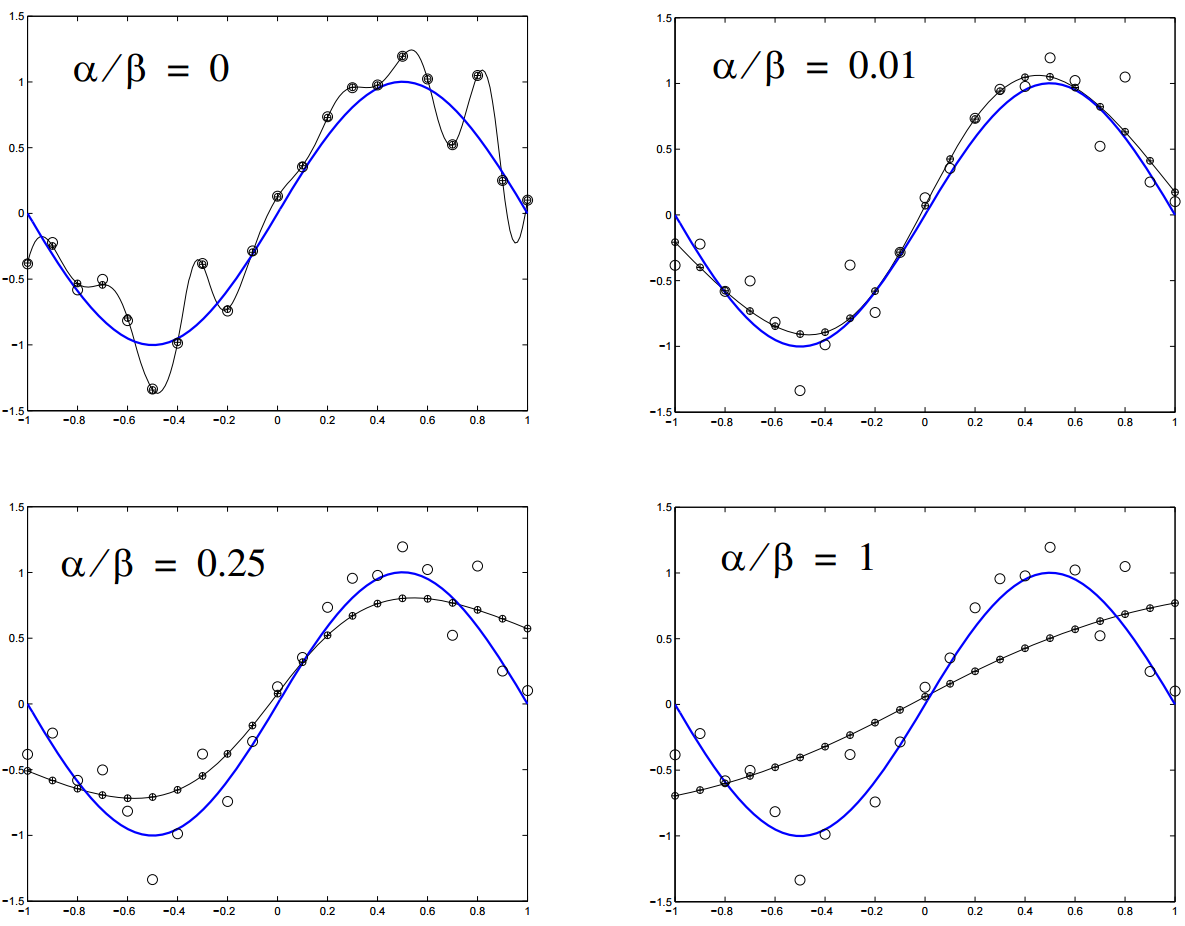
Другая техника, довольно дорогостоящая в плане вычислений, — глобальный поиск. Здесь алгоритм поиска используется для дифференциации архитектуры сети и нахождения ее оптимального варианта. Обычно для этого берут алгоритм генерации, о котором будет сказано ниже.
Что такое «аутпуты»?
Нейронную сеть можно использовать для регрессии или классификации. В первой модели мы работаем с единичным значением на выходе. То есть нужен всего один нейрон выхода. Во второй модели нейрон выхода нужен для каждого класса, к которому может принадлежать паттерн, в отдельности. Если классы не известны – используются самоорганизующиеся карты.Подытожим эту часть рассказа. Лучший подход для определения размера сети – следовать принципу Оккама. То есть для двух моделей с одинаковой производительностью, модель с меньшим количеством параметров будет генерализировать успешней. Это не значит, что нужно обязательно выбирать простую модель в целях повысить производительность. Верно обратное утверждение: множество скрытых нейронов и слоев не гарантирует превосходство. Слишком много внимание сегодня уделяется большим сетям, и слишком мало самим принципам их разработки. Больше – не всегда лучше.
5. К нейронной сети применимо множество обучающих алгоритмов
Обучающий алгоритм призван оптимизировать вес нейронной сети, пока не наткнется на некое условие остановки. Это может быть связано с появлением ошибки в тренировочном сете на приемлемом уровне точности (например, когда работа сети на этапе валидации начинает ухудшаться). Это может быть точка, когда израсходован некий вычислительный бюджет сети. Самый популярный вариант алгоритма – метод обратного распространения с использованием градиентного стохастического спуска. Обратное распространение состоит из двух шагов:- Прямое прохождение: обучающие данные проходят через сеть, записывается выходной сигнал и подсчитываются ошибки.
- Обратное распространение: сигнал ошибки протаскивается обратно через сеть, вес сети оптимизируется с использованием градиентного спуска.
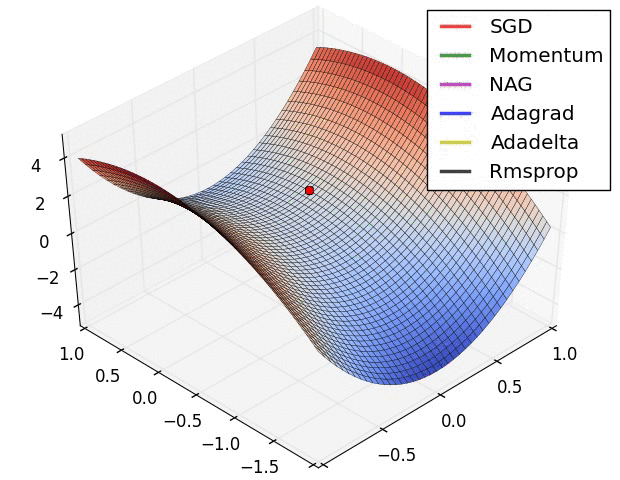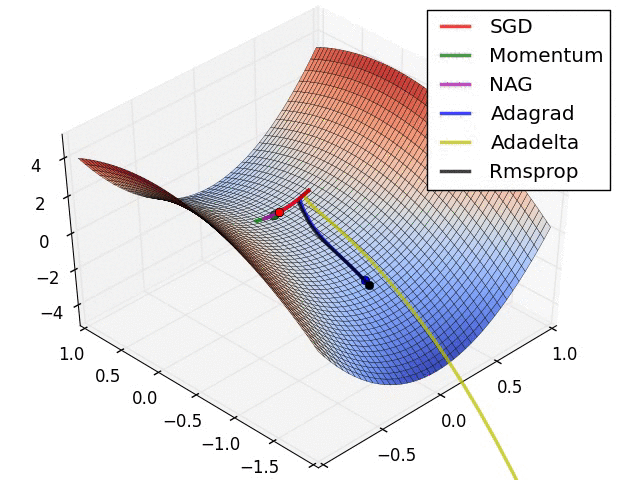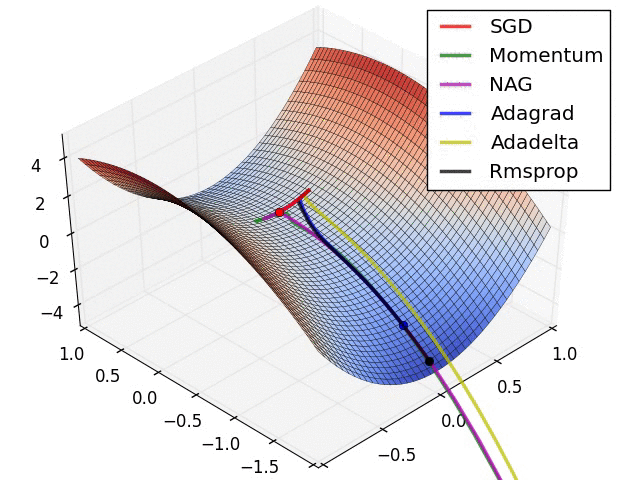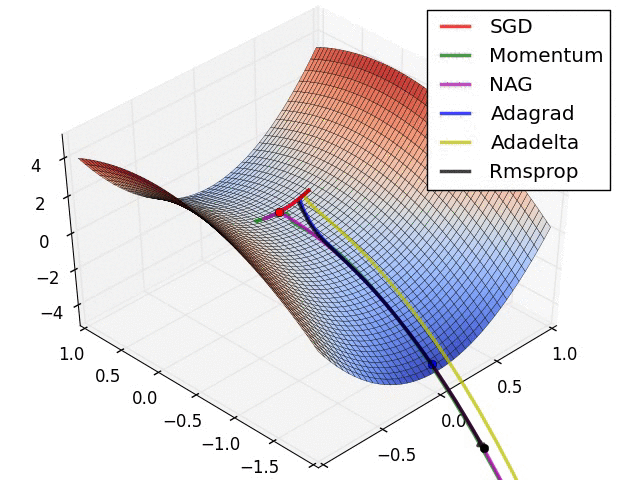
Но все эти алгоритмы не могут преодолеть локальный минимум, и менее полезны, когда пытаются одновременно оптимизировать архитектуру и нагрузку сети. Нужен алгоритм глобальной оптимизации. Это может быть метод роя частиц (Particle Swarm Optimization) или генетический алгоритм. Вот, как это работает.
Векторное представление нейронной сети кодирует нейронную сеть по вектору нагрузки, каждый из векторов представляет вес соединения в сети. Мы можем обучать сеть, используя мета-эвристический поисковой алгоритм. На слишком больших сетях метод работает плохо, потому что сами векторы становятся слишком большими.
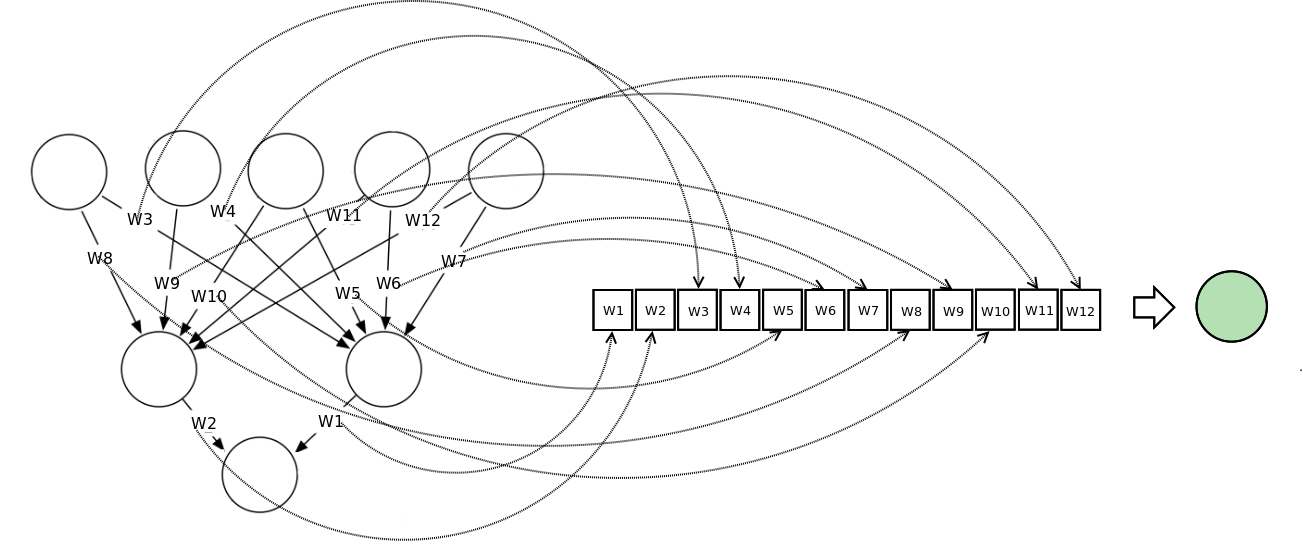
На диаграмме показано, как нейронная сеть может быть представлена в векторной нотации
Метод роя частиц обучает сеть через построение популяции/роя. Каждая нейронная сеть здесь представлена как вектор нагрузки и скорректирована по отношению к позиции глобальной лучшей частицы и ее собственной лучшей позиции.
Эта функция приспособления просчитывается как сумма квадратов ошибок реконструированной нейронной сети после завершения одного прямого прохождения. Выгоду получаем на оптимизации скорости обновления весов связей. Если весы будут регулироваться слишком быстро, сумма квадратов ошибок стагнирует, обучение не происходит.
Генетический алгоритм строит популяцию вектора, представляющего нейронную сеть. Далее с ней проводятся три последовательные операции для улучшения работы сети:
- Выборка: после каждого прямого прохождения подсчитывается сумма квадратов ошибок, популяция нейронной сети ранжируется. Верхний процент популяции выбирается для выживания и используется для кроссовера.
- Кроссовер: верхний x% генов популяции соревнуется между собой, получаем некое новое потомство, каждое потомство представляет, по сути, новую нейронную сеть.
- Мутация: этот оператор требует поддержки генетического разнообразия в популяции, небольшой процент ее отбирается для прохождения мутации, то есть некоторые весы сети будут регулироваться случайно.
6. Нейронным сетям не всегда нужен большой объем данных
Нейронные сети могут использовать три основных обучающих стратегии: контролируемое обучение, неконтролируемое и усиленное обучение. Для первой, нужны, по крайней мере, два обучающих сета данных. Один из них будет состоять из входных с ожидаемыми выходными сигналами, второй с входными без ожидаемых выходных. Оба должны включать маркированные данные, то есть паттерны с изначально неизвестным предназначением.Неконтролируемая стратегия обычно используется для выявления скрытых структур в немаркированных данных (например, скрытых цепей Маркова). Принцип работы тот же, что и у кластерных алгоритмов. Усиленное обучение основано на простом допущении о наличие выигрышных сетей и помещении их в плохие условия. Два последних варианта не подразумевают использование маркированных данных, поэтому правильный выходной сигнал здесь неизвестен.
Неконтролируемое обучение
Одна из самых популярных архитектур для такого типа сети – самоорганизующаяся карта. По сути, это техника масштабирования в нескольких измерениях, которая конструирует приближение функции плотности вероятности какого-либо основного цикла данных. Z – сохраняет топологическую структуру сета данных, картируя векторы входных сигналов – zi. Она взвешивает векторы — vj, в будущей карте V. Сохранение топологической структуры означает, что, если два вектора стоят близко друг к другу в Z, нейроны, к которым они относятся, также будут расположены в V. Более подробно можно почитать здесь.Усиленное обучение
Эта стратегия состоит из трех компонентов: установки на то, как нейронная сеть будет принимать решения, используя технические и фундаментальные индикаторы, функции достижения цели, которая отделяет зерна от плевел, и функции значения, нацеленной на перспективу.7. Нейронную сеть нельзя обучить на любых данных
Одна из главных проблем, почему нейронная сеть может не работать, заключается в том, что нередко данные плохо готовят перед загрузкой в систему. Нормализация, удаление избыточной информации, резко отклоняющихся значений должны проводиться перед началом работы с сетью, чтобы улучшить ее производственные возможности.Мы знаем, что у нас есть слои перцептронов, соединенных по весу. Каждый перцептрон содержит функцию активации, который, в свою очередь, разделены по рангу. Входные сигналы должны быть масштабированы, исходя из этого ранга, чтобы сеть могла различать входные паттерны. Это предпосылки для нормализации данных.
Резко выделяющиеся значения или намного больше или намного меньше большинства других значений в наборе данных для сета. Такие вещи могут вызвать проблемы в применении статистических методов – регрессии и подгонки кривой. Потому что система постарается приспособить эти значения, производительность ухудшится. Выявить такие значения самостоятельно может быть проблематично. Здесь можно посмотреть инструкцию по техникам работы с резко отклоняющимися значениями.
Внесение двух или более независимых переменных, которые близко коррелируют друг с другом также может вызвать снижение способности к обучению. Удаление избыточных переменных, ко всему прочему, ускоряет время обучения. Для удаления избыточных соединений и перцептронов можно использовать адаптивные нейронные сети.
8. Нейронные сети иногда требуется обучать заново
Даже если вы настроили должным образом нейронную сеть, и она торгует успешно в выборке и за ее пределами, еще не значит, что через некоторое время она не перестанет работать. Дело не в ней, дело в том, как ведет себя финансовый рынок. Финансовые рынки – комплексные адаптивные системы. То, что работает сегодня, может не работать завтра. Эту их характеристику называют нестационарностью или динамической оптимизацией. Нейронные сети пока не умеют с этим справляться.Динамическая среда финансовых рынков очень сложная штука для моделирования нейронной сетью. Есть два выхода из ситуации: время от времени переобучать сеть или использовать динамическую нейронную сеть. Она призвана отслеживать изменения в среде по времени и приспосабливать их к архитектуре и нагрузке системы. Для решения динамических проблем можно использовать многосторонние мета-эвристические алгоритмы оптимизации. Они будут отслеживать изменения к локальному опыту по времени. Один из вариантов – оптимизация множественного роя, производная от метода роя частиц. Генетические алгоритмы с улучшенной диверсификацией и памятью также могут быть полезны в динамичной среде.
9. Нейронная сеть – это не черный ящик
Сама по себе нейронная сеть – это «черный ящик». Это создает определенные проблемы для людей, которые работают или планируют с ней работать. Например, фондовые управляющие не понимают, как система принимает решения по финансовым операциям. Отсюда получается, что нельзя рассчитать риск трейдинговой стратегии, которой обучилась сеть. Опять же банки, использующие нейронную сеть для просчетов кредитных рисков, не могут верифицировать ее позиции по кредитному рейтингу для тех или иных клиентов. Для этих целей были придуманы алгоритмы извлечения правил работы сети. Знания могут быть вытащены из сети в виде математических формул, символической логики, нечеткой логики, дерева решений.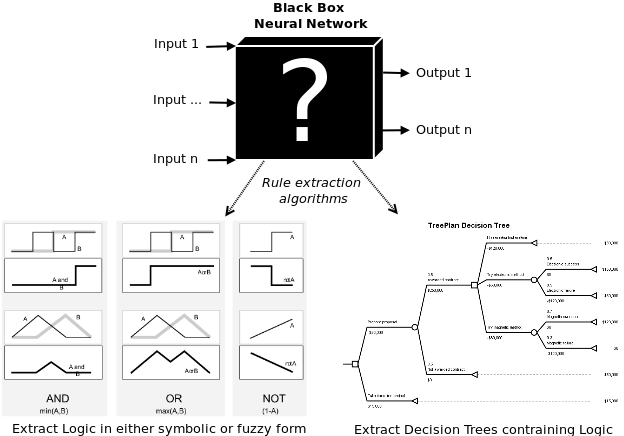
Математические правила: некоторые алгоритмы позволяют извлекать множественные строки линейной регрессии. Проблема в том, что зачастую они понятны только в контексте работы «черного ящика».
Пропозициональная логика: раздел математической логики, который имеет дело с дискретными значениями переменных. Эти переменные A и B чаще всего имеют значения «верно» — «неверно», но также могут иметь значения дискретного уровня – «покупать, «удерживать», «продавать».
К ним применимы логические операции: OR, AND и XOR. Результаты этих операция называются предикатами, количественные значения которых также можно рассчитать. Между предикатами и пропозициональной логикой есть различие. Если у нас простая нейронная сеть с ценой (P), простым скользящим средним (SMA), экспоненциальным скользящим средним (EMA) в качестве входных сигналов, и мы хотим извлечь тренд стратегии в пропозициональной логике, мы действуем по следующим правилам:
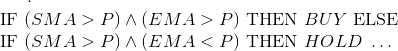
Нечеткая логика (fuzzy logic) – это то место, где встречается вероятность и пропозициональная логика. Последняя имеет дело с абсолютами – «купить», «продать», «верно», «неверно», 0 или 1. Трейдер никак не может подтвердить подлинность этих результатов. Нечеткая логика преодолевает это ограничение, вводя функцию членства, обозначающую принадлежность переменной к определенной области, домену. Например, компания (GOOG) имеет значение 0,7 в домене BUY и 0,3 в домене SELL. Комбинация такой логики и нейронной сети называется нейро-нечеткая система.
Дерево решений показывает, как принимаются решения при загрузке определенной информации. В этой статье можно почитать, как построить анализ безопасности дерева решения, используя генетическое программирование.
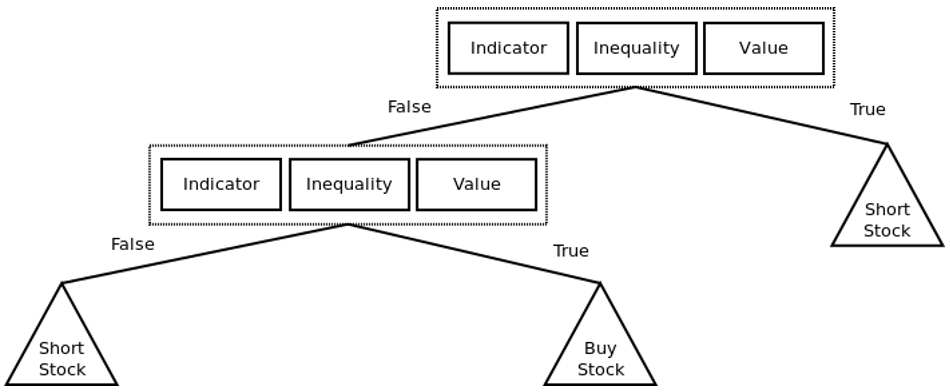
Пример простой стратегии онлайн-трейдинга, представленной в виде дерева решений. Треугольники представляют узлы решений (например, BUY, HOLD или SELL для покупки, удержания или продажи акций). Каждый элемент представляет собой пару <indicator, inequality,="" value="">. Например, <sma,>, 25> or <ema, <="," 30="">.
10. Нейронную сеть создать и применить нетрудно
Если говорить о практике, создать нейронную сеть с нуля довольно проблематично. К счастью, сейчас существуют сотни пакетов с открытым доступом, которые делают работу с нейронными сетями немного проще. Ниже приведен список таких пакетов, которые можно пользовать в количественном анализе в финансовой сфере. Список далеко не полный, инструменты даны в алфавитном порядке.Caffe Сайт - http://caffe.berkeleyvision.org/ Репозиторий на GitHub - https://github.com/BVLC/caffeEncog Сайт - http://www.heatonresearch.com/encog/ Репозиторий на GitHub - https://github.com/encog
h3O Сайт - http://h3o.ai/ Репозиторий на GitHub - https://github.com/h3oai
Google TensorFlow Сайт - http://www.tensorflow.org/ Репозиторий на GitHub - https://github.com/tensorflow/tensorflow
Microsoft Distributed Machine Learning Tookit Сайт - http://www.dmtk.io/ Репозиторий на GitHub - https://github.com/Microsoft/DMTK
Microsoft Azure Machine Learning Сайт - https://azure.microsoft.com/en-us/services/machine-learning Репозиторий на GitHub — github.com/Azure?utf8=%E2%9C%93&query=MachineLearning
MXNet Сайт - http://mxnet.readthedocs.org/en/latest/ Репозиторий на GitHub - https://github.com/dmlc/mxnet
Neon Сайт - http://neon.nervanasys.com/docs/latest/index.html Репозиторий на GitHub - https://github.com/nervanasystems/neon
Theano Сайт - http://deeplearning.net/software/theano/ Репозиторий на GitHub - https://github.com/Theano/Theano
Torch Сайт - http://torch.ch/ Репозиторий на GitHub - https://github.com/torch/torch7
SciKit Learn Сайт - http://scikit-learn.org/stable/ Репозиторий на GitHub - https://github.com/scikit-learn/scikit-learn
Заключение
Нейронные сети – это класс мощных алгоритмов машинного обучения. В их основе лежат статистические методы анализа. Вот уже много лет их с успехом применяют к разработке стратегий трейдинга и финансовых моделей. Несмотря на это, у нейронных сетей не очень хорошая репутация, основанная на неудачах практического применения. В большинстве случаев причины неудач лежат в неадекватных конструкторских решениях и общем непонимании того, как они работают. В этой статье автор попытался артикулировать лишь некоторые из самых распространенных заблуждений в надежде, что кому-нибудь эта информация пригодится в реальной практике.Другие материалы по теме от ITinvest:
habr.com
Mirocana — нейронная сеть для торговли на крипторынке

Спонсорский материал
Начну с вопроса: А Вы когда-нибудь торговали на рынке финансовых инструментов? Нет, не просто купили акцию, облигацию или даже криптовалюту на бирже, а именно торговали — то есть осуществляли регулярные сделки по купле-продаже активов на протяжении длительного времени. Те из наших читателей, кто действительно этим занимался, подтвердят, что дело это не из простых. Очень не простых.
Представим вкратце торговый день трейдера-любителя, которого зовут, например, Иван. У него на брокерском счету есть деньги — выделенные из личного или семейного бюджета деньги. И вот, ему надо принять первое торговое решение. Допустим, что он хочет торговать валютную пару доллар-рубль. Мозг Ивана тут же начинает генерить множество вопросов – когда покупать, на какую сумму, а покупать сейчас или подождать, может цена упадет, а что вообще влияет сегодня на курс, в какую сторону он сегодня вероятно пойдет. Иван начинает читать экономические и финансовые новости, чтобы попытаться спрогнозировать следующее ценовое движение валютной пары. Однако, как это неудивительно, никакого однозначного прогноза из новостей сделать он не сможет, т.к. зачастую они приводят совершенно к противоречивым выводам.
Тем не менее, наш герой все-таки набрался смелости и решил купить актив. Тут возникает следующий вопрос – а что дальше? И мозг Ивана снова начинает нагреваться в поиске ответов на вопросы – когда продавать, ставить ли стоп, ставить ли тейк-профит, на каких уровнях т.д. Созерцание ценовых движений будет заставлять Ивана вспоминать все, что он прочитал по теханализу, высматривать фигуры на японских свечах, искать паттерны, накладывать индикаторы – все в поиске того субъективного триггера, который подскажет ему его следующий шаг.
Теперь, добавьте к этому примеру пару параметров из нашей реальной жизни. Иван как трейдер-любитель где-то работает, т.е. не может все свое время уделить изучению финансовой литературы и торговле на рынке. У Ивана есть семья, друзья, обязательства и т.д. Представьте, что он торгует внутри дня (с этого начинают многие новички, не понимая, что этот таймфрейм один из самых сложных). Добавьте к этому тот факт, что возможная прибыль на сделку будет исчисляться сотнями, ну тысячами, рублей, если без маржи и счет в несколько сотен тысяч «деревянных». Не забудьте прибавить и серию из неудачно сделанных подряд трейдов – без них никак. Теперь представим, что это все Иван делает в течение месяца. В каком психологическом состоянии будет после всего этого наш герой? Могу со знанием дела Вам сказать, что за месяц на фондовом рынке можно легко превратиться в невротика. Потерять капитал. Спровоцировать на пустом месте конфликты с близкими.
Определенным решением описанной ситуации могла бы стать торговля по системе, т.е. когда трейдер заранее вырабатывает себе систему принятия торговых решений – когда продавать, когда покупать, на какую сумму, что делать при резкой просадке, что делать при резком взлете цены, когда открываться после закрытия сделки и т.д. Если у него эти правила еще и четко прописаны, что также бывает очень редко, – это может сберечь нервы, но не избавит от напряжения в целом. Человеческие факторы как то жадность, страх, гордость – рано или поздно дадут о себе знать при принятии торговых решений.
Следующими надстройками к цивилизованному трейдингу являются роботизированные советники и алгоритмическая торговля. Первые доступны для широких масс и позволяют делать сделки лишь тогда, когда советник дает сигнал. Вторая — доступна людям со знаниями программирования, когда разрабатываются полностью автоматизированные системы торговли по заданным правилам. Обе эти «надстройки» к торговле существенно снижают влияние человеческого фактора на принятие торговых решений и продлевают жизнь Вашей нервной системе.
К сожалению, и у них имеются недостатки. Заложенные в советники алгоритмы, как правило, неизвестны. Разработка собственного алгоритма трудоемка – надо придумать и формализовать в коде торговые правила, которые обыгрывали бы рынок на длительном временном отрезке, предусмотреть риск- и мани-менеджмент, учесть операционные комиссии, провести бэк- и фронт-тестинг. Доведение такого механизма до полной автоматизации – доступно крайне ограниченному кругу лиц и компаний и занимает не мало времени. Еще и инфраструктурные вопросы придется решать.
Значит ли перечисленное выше, что доступ на рынки финансовых инструментов недоступен для широких масс? Ответ – конечно же, нет. Более того, все ведущие финансисты и экономисты советуют, и мы разделяем их мнение, чтобы каждый человек, каждая семья имела бы экспозицию части своих денег к фондовому рынку. Просто ее процент должен быть строго лимитирован определенным процентом от уровней дохода и терпимости к риску.
Технологии, однако, не стоят на месте и появляются другие – новые механизмы торговли на финансовых рынках, основанные, казалось бы, на вещах невероятных. Возвращаясь к нашему трейдеру-любителю Ивану, представьте, что в его распоряжении перед принятием каждого торгового решения имеется вся необходимая информация. То есть не просто список новостных заметок и исторических данных, а практически все, что доступно – это и опыт других трейдеров, и имеющиеся на момент принятия торгового решения данные по заявкам, «стопам» и текущим позициям других участников рынка. Если бы Иван смог обработать всю совокупность этих сведений, он смог бы с высокой степенью достоверностью оценить сложившийся на текущий момент баланс сил быков и медведей и совершить верную сделку. Но наш трейдер-любитель такого не может. Зато это может делать Mirocana.
Mirocana – это разрабатываемая нашими соотечественниками система искусственного интеллекта, «заточенная» на торговле на финансовых рынках. Причем на любых – хоть на криптовалютных биржах тоже. Она не требует какого-либо участия трейдера-любителя. Полностью автоматизирована. Не требует специальной установки – достаточно привязать ее к Вашему брокеру или бирже. Вам лишь нужно настроить желаемый уровень дохода и принять уровень соответствующего риска. Все. По-моему, это близко к трейдерскому «святому граалю» – мифической торговой системе, подавляющее большинство сделок в которой прибыльны при любых движениях рынка.
Как же Mirocana работает? Разработчики проекта создали самообучающуюся нейронную сеть, заложили в нее в качестве базовых вариантов множество различных торговых стратегий, причем не только основанных на теханализе, но и те, что торгуют по новостям, а также те, которые анализируют фундаментальные данные по активам, и добавили ко всему этому опыт других реальных трейдеров. Таким образом, заложенный в Мирокану искусственный интеллект обладает для анализа полным объемом информации. Ну, а далее – дело техники – прогонять на основе известных данных различные стратегии, выбирать лучшие исходы, формировать на их основе новые стратегии. То есть сделано все, чтобы добиться устойчивых показателей по доходности при соблюдении заданного уровня риска.
Система заработает в полном объеме уже в январе 2018 года. Остается чуть более месяца, чтобы на льготных условиях получить доступ к Mirocana. Желающие в рамках открытого ICO могут приобрести токены MIRO и стать одними из первых, на кого станет работать в совокупности практически весь трейдерский интеллект финансового и криптовалютного рынков.
Сейчас проект Mirocana предлагает инвесторам три продукта. В рамках «рынка акций» с марта 2018 года будет открыт доступ к основным американским торговым площадкам NASDAQ и NYSE. Он, к сожалению, будет доступен только для институционалов и частных трейдеров с крупным капиталом – доступ получают только топ 200 держателей токенов MIRO по итогу токен-сейла.
Доступ к пакету «валютный рынок» можете приобрести за 10 тыс MIRO – около 3 тыс долларов США. В рамках него Mirocana будет трудиться для Вас на рынке Forex (не путайте с форекс-дилерами, которые заманивают новичков, предлагают 100 или 1000 уе на счету и внушают Вам, что Вы боги трейдинга, а потом за 3-5 сделок от ваших денег на счетах не остается ничего) и предсказывать курсы 125 валютных пар, доступных у брокера OANDA. Торговлю можно будет начать уже с января 2018 года.
Ну и на конец третий вариант — наш любимый, учитывая нашу специализацию, — это «криптовалютный рынок». В рамках этого пакета уже за 5 тыс. MIRO можно получить весь функционал Mirocana для прогнозирования и торговли криптовалютными парами. Работает с биржей Poloniex. В будущем планируется интеграция и других крупных площадок. Ждем февраля.
MIRO можно купить за эфир биткоины, хрипл, монеро, лайткоин и старым добрым способом – по кредитке. Для того, чтобы каждый смог убедиться в эффективности заложенной логики и реализации системы Mirocana, разработчики проекта не будут брать с подписантов комиссий в течение аж восьми месяцев. Это действительно заманчивый расклад. В дальнейшем 25% с прибыли будет «уходить» к руководителям проекта. Если кому-то покажется, что отдавать четверть прибыли – это много, то вы не сталкивались с традиционными управляющими компаниями. Естественно разброс есть, но размер в 25% от прибыли является минимальным средним уровнем, которую УК заберет себе. Правда еще помимо этого будет брать себе так называемый management fee, т.е. плату за управление, от стоимости чистых активов, т.е. вне зависимости от того «в плюс» или «в минус» финансовая компания управляет вашими деньгами. Размер такой комиссии обычно составляет 2-3%.
ICO закончится чуть меньше чем через месяц — 19 декабря. Время еще есть, но затягивать не стоит. Думаю, нашему трейдеру-любителю Ивану Mirocana пришлась бы очень по душе…, да и по кошельку тоже.
coinspot.io
Прогнозирование цен с помощью нейронных сетей
В последние несколько лет мы наблюдаем взрыв интереса к нейронным сетям, которые успешно применяются в самых различных областях - бизнесе, медицине, технике, геологии, физике. Нейронные сети вошли в практику везде, где нужно решать задачи прогнозирования, классификации или управления. Такой впечатляющий успех определяется несколькими причинами:
- Богатые возможности. Нейронные сети - исключительно мощный метод моделирования, позволяющий воспроизводить чрезвычайно сложные зависимости. В частности, нейронные сети нелинейны по свой природе. На протяжении многих лет линейное моделирование было основным методом моделирования в большинстве областей, поскольку для него хорошо разработаны процедуры оптимизации. В задачах, где линейная аппроксимация неудовлетворительна, линейные модели работают плохо. Кроме того, нейронные сети справляются с "проклятием размерности", которое не позволяет моделировать линейные зависимости в случае большого числа переменных
- Простота в использовании. Нейронные сети учатся на примерах. Пользователь нейронной сети подбирает представительные данные, а затем запускает алгоритм обучения, который автоматически воспринимает структуру данных. При этом от пользователя, конечно, требуется какой-то набор эвристических знаний о том, как следует отбирать и подготавливать данные, выбирать нужную архитектуру сети и интерпретировать результаты, однако уровень знаний, необходимый для успешного применения нейронных сетей, гораздо скромнее, чем, например, при использовании традиционных методов статистики.
Нейронные сети привлекательны с интуитивной точки зрения, ибо они основаны на примитивной биологической модели нервных систем. В будущем развитие таких нейро-биологических моделей может привести к созданию действительно мыслящих компьютеров.[1]
Предсказание финансовых временных рядов - необходимый элемент любой инвестиционной деятельности. Сама идея инвестиций - вложения денег сейчас с целью получения дохода в будущем - основывается на идее прогнозирования будущего. Соответственно, предсказание финансовых временных рядов лежит в основе деятельности всей индустрии инвестиций - всех бирж и небиржевых систем торговли ценными бумагами.
Известно, что 99% всех сделок - спекулятивные, т.е. направлены не на обслуживание реального товарооборота, а заключены с целью извлечения прибыли по схеме "купил дешевле - продал дороже". Все они основаны на предсказаниях изменения курса участниками сделки. Причем, что немаловажно, предсказания участников каждой сделки противоположны друг другу. Так что объем спекулятивных операций характеризует степень различий в предсказаниях участников рынка, т.е. реально - степень непредсказуемости финансовых временных рядов.
Это важнейшее свойство рыночных временных рядов легло в основу теории "эффективного" рынка, изложенной в диссертации Луи де Башелье (L.Bachelier) в 1900 г. Согласно этой доктрине, инвестор может надеяться лишь на среднюю доходность рынка, оцениваемую с помощью индексов, таких как Dow Jones или S&P500 для Нью-Йоркской биржи. Всякий же спекулятивный доход носит случайный характер и подобен азартной игре на деньги (а что то в этом есть, не находите?). В основе непредсказуемости рыночных кривых лежит та же причина, по которой деньги редко валяются на земле в людных местах: слишком много желающих их поднять.
Теория эффективного рынка не разделяется, вполне естественно, самими участниками рынка (которые как раз и заняты поиском "упавших" денег). Большинство из них уверено, что рыночные временные ряды, несмотря на кажущуюся стохастичность, полны скрытых закономерностей, т.е. в принципе хотя бы частично предсказуемы. Такие скрытые эмпирические закономерности пытался выявить в 30-х годах в серии своих статей основатель волнового анализа Эллиот (R.Elliott).
В 80-х годах неожиданную поддержку эта точка зрения нашла в незадолго до этого появившейся теории динамического хаоса. Эта теория построена на противопоставлении хаотичности и стохастичности (случайности). Хаотические ряды только выглядят случайными, но, как детерминированный динамический процесс, вполне допускают краткосрочное прогнозирование. Область возможных предсказаний ограничена по времени горизонтом прогнозирования, но этого может оказаться достаточно для получения реального дохода от предсказаний (Chorafas, 1994). И тот, кто обладает лучшими математическими методами извлечения закономерностей из зашумленных хаотических рядов, может надеяться на большую норму прибыли - за счет своих менее оснащенных собратьев.
В последнее десятилетие наблюдается устойчивый рост популярности технического анализа - набора эмпирических правил, основанных на различного рода индикаторах поведения рынка. Технический анализ сосредотачивается на индивидуальном поведении данного финансового инструмента, вне его связи с остальными ценными бумагами. Но технический анализ очень субъективен и плохо работает на правом краю графика – именно там, где нужно прогнозировать направление цены. Поэтому все большую популярность приобретает нейросетевой анализ, поскольку в отличие от технического, не предполагает никаких ограничений на характер входной информации. Это могут быть как индикаторы данного временного ряда, так и сведения о поведении других рыночных инструментов. Недаром нейросети активно используют именно институциональные инвесторы (например, крупные пенсионные фонды), работающие с большими портфелями, для которых особенно важны корреляции между различными рынками.
Нейросетевое моделирование в чистом виде базируется лишь на данных, не привлекая никаких априорных соображений. В этом его сила и одновременно - его ахиллесова пята. Имеющихся данных может не хватить для обучения, размерность потенциальных входов может оказаться слишком велика.
Поэтому для хорошего прогноза нужно пользоваться во-первых, очень качественно подготовленными данными, а во-вторых, нейропакетами с большой функциональностью.
Подготовка данных
Для начала работы нужно подготовить данные, от правильности этой работы зависит 80% успеха.
Гуру говорят, что в качестве входов и выходов нейросети не следует выбирать сами значения котировок Ct. Действительно значимыми для предсказаний являются изменения котировок. Поскольку эти изменения, как правило, гораздо меньше по амплитуде, чем сами котировки, между последовательными значениями курсов имеется большая корреляция - наиболее вероятное значение курса в следующий момент равно его предыдущему значению C(t+1)=C(t)+delta(C)=C(t).
Между тем, для повышения качества обучения следует стремиться к статистической независимости входов, то есть к отсутствию подобных корреляций. Поэтому в качестве входных переменных логично выбирать наиболее статистически независимые величины, например, изменения котировок delta(С) или логарифм относительного приращения log(C(t)/C(t+1)).
Последний выбор хорош для длительных временных рядов, когда уже заметно влияние инфляции. В этом случае простые разности в разных частях ряда будут иметь различную амплитуду, т.к. фактически измеряются в различных единицах. Напротив, отношения последовательных котировок не зависят от единиц измерения, и будут одного масштаба несмотря на инфляционное изменение единиц измерения. В итоге, большая стационарность ряда позволит использовать для обучения большую историю и обеспечит лучшее обучение.
Отрицательной чертой погружения в лаговое пространство является ограниченный "кругозор" сети. Технический анализ же, напротив, не фиксирует окно в прошлом, и пользуется подчас весьма далекими значениями ряда. Например, утверждается, что максимальные и минимальные значения ряда даже в относительно далеком прошлом оказывают достаточно сильное воздействие на психологию игроков, и, следовательно, должны быть значимы для предсказания. Недостаточно широкое окно погружения в лаговое пространство не способно предоставить такую информацию, что, естественно, снижает эффективность предсказания. С другой стороны, расширение окна до таких значений, когда захватываются далекие экстремальные значения ряда, повышает размерность сети, что в свою очередь приводит к понижению точности нейросетевого предсказания - уже из-за разрастания размера сети.
Выходом из этой, казалось бы, тупиковой ситуации являются альтернативные способы кодирования прошлого поведения ряда. Интуитивно понятно, что чем дальше в прошлое уходит история ряда, тем меньше деталей его поведения влияет на результат предсказаний. Это обосновано психологией субъективного восприятия прошлого участниками торгов, которые, собственно, и формируют будущее. Следовательно, надо найти такое представление динамики ряда, которое имело бы избирательную точность: чем дальше в прошлое - тем меньше деталей, при сохранении общего вида кривой.
Весьма перспективным инструментом здесь может оказаться вейвлетное разложение (wavelet decomposition). Оно эквивалентно по информативности лаговому погружению, но легче допускает такое сжатие информации, которое описывает прошлое с избирательной точностью.
Выбор программного обеспечения
Для работы с нейросетями предназначено множество специализированных программ, одни из которых являются более-менее универсальными, а другие – узкоспециализированными. Проведем краткий обзор некоторых программ :
1. Matlab – настольная лаборатория для математических вычислений, проектирования электрических схем и моделирования сложных систем. Имеет встроенный язык программирования и весьма богатый инструментарий для нейронных сетей – Anfis Editor (обучение, создание, тренировка и графический интерфейс), командный интерфейс для программного задания сетей, nnTool – для более тонкой конфигурации сети.
2. Statistica – мощнейшее обеспечение для анализа данных и поиска статистических закономерностей. В данном пакете работа с нейросетями представлена в модуле STATISTICA Neural Networks (сокращенно, ST Neural Networks, нейронно-сетевой пакет фирмы StatSoft), представляющий собой реализацию всего набора нейросетевых методов анализа данных.
3. BrainMaker – предназначен для решения задач, для которых пока не найдены формальные методы и алгоритмы, а входные данные неполны, зашумлены и противоречивы. К таким задачам относятся биржевые и финансовые предсказания, моделирование кризисных ситуаций, распознавание образов и многие другие.
4. NeuroShell Day Trader - нейросетевая система, которая учитывает специфические нужды трейдеров и достаточно легка в использовании. Программа является узкоспециализированной и как раз подходит для торговли, но по своей сути слишком близка к черному ящику.
5. Остальные программы являются менее распространенными.
Для первичной работы вполне подойдет Matlab, в нем и будем пытаться определить степень пригодности нейросетей для прогнозирования рынка Forex.
Ознакомиться с комплексом MatLab можно в википедии https://ru.wikipedia.org/wiki/MATLAB
Много материалов по программе предоставлено на сайте http://matlab.exponenta.ru/Приобрести программу можно через компанию SoftLine http://soft.softline.ru/author_page_all.php?id=410
Эксперимент
Подготовка данных
Данные очень удобно можно получить стандартными средствами MetaTrader:
Сервис -> Архив котировок -> Экспорт
В результате получаем файл в формате *.csv, который является первичным сырьем для подготовки данных. Для преобразования полученного файла в удобный для работы файл *.xls нужно произветси импорт данных из файла *.csv. Для этого в excel нужно произвести следующие махинации:
Данные -> Импорт внешних данных -> Импортировать данные и указать подготовленный первичный файл. В мастере импорта все необходимые действия выполняются в 3 шага:



На 3 шаге необходимо поменять разделитель целой и дробной части на точку, делается это при нажатии кнопки Подробнее…
Для того чтобы данные были восприняты как цифры, а не как строки, нужно поменять разделитель целой и дробной части на точку:
Сервис -> Параметры -> Международные -> Разделитель целой и дробной части.
На скриншотах показан пример сохранения цен открытия и закрытия, остальные данные пока не нужны.
Теперь данные надо преобразовать в соответствии с тем, что и как мы хотим прогнозировать. Составим прогноз цены закрытия будущего дня по четырем предыдущим (данные идут в пяти столбцах, цены в хронологическом порядке).
1.2605 |
1.263 |
1.2641 |
1.2574 |
1.2584 |
1.2666 |
1.263 |
1.2641 |
1.2574 |
1.2584 |
1.2666 |
1.2569 |
1.2641 |
1.2574 |
1.2584 |
1.2666 |
1.2569 |
1.2506 |
1.2574 |
1.2584 |
1.2666 |
1.2569 |
1.2506 |
1.2586 |
1.2584 |
1.2666 |
1.2569 |
1.2506 |
1.2586 |
1.2574 |
Благодаря нехитрым манипуляциям в excel данные подготавливаются за пару минут. Пример подготовленного файла с данными можно взять в прикрепленых файлах.
Для того, чтобы Matlab распознал файлы, необходимо, чтобы подготовленные данные были сохранены в файлах с расширением *.txt или *.dat. Сохраним их в файлах *.txt. Далее каждый файл разбиваем на два множества – для обучения сети (выборка) и для ее тестирования (вне выборки). Подготовленные таким образом euro.zip данные пригодны для дальнейшей работы
Знакомство с Matlab
Из командной строки по команде anfisedit запускаем пакет ANFIS. Редактор состоит из четырех панелек – для данных (Load data), для генерации сети (Generate FIS), для тренировки (Train FIS)и для ее тестирования (Test FIS). Верхняя панель предназначена для просмотра структуры полученной нейросети (ANFIS Info).
Более подробно с работой пакета можно ознакомиться по приведенным ниже ссылкам.
http://forest.akadem.ru/library/matlab/fuzzylogic/book1/7_6.html
http://matlab.exponenta.ru/fuzzylogic/book1/1_7_5_7.php
Для начала работы загружаем данные, подготовленные на предыдущих этапах. Для этого нажимаем кнопку Load Data и указываем файл с данными выборки. После этого создаем нейросеть нажатием кнопки Generate FIS.

Для каждой из входных переменных зададим по 3 лингвистические переменные с треугольной функцией принадлежности. В качестве функции принадлежности выходной функции зададим линейную функцию.

Для обучения нейросетей в пакете AnfisEdit предусмотрено 2 алгоритма обучения – обратного распространения и гибридный. При гибридном способе обучения сеть обучается буквально за пару-тройку проходов. На тренировочной выборке (60 значений) после обучения прогноз сети отличается от реального на несколько пунктов.

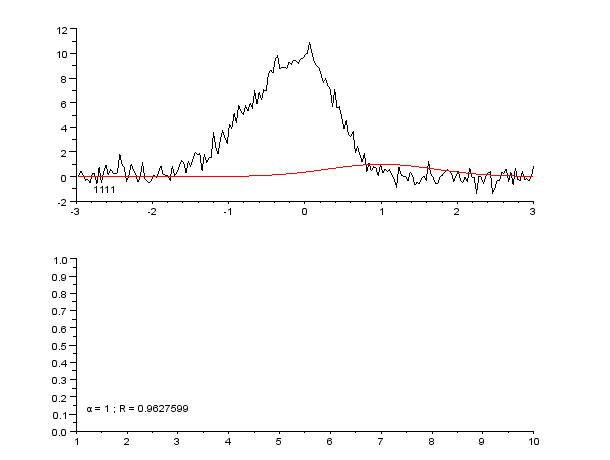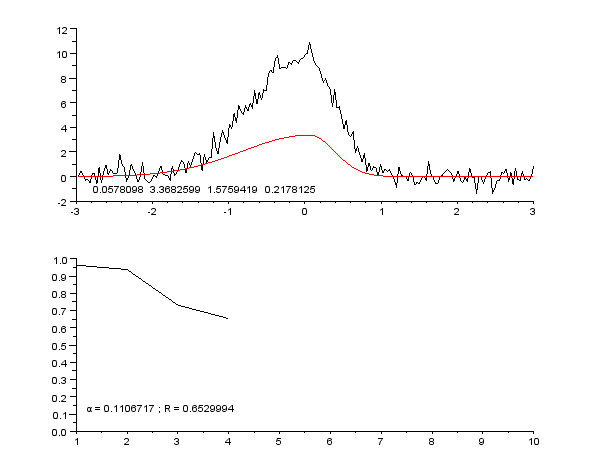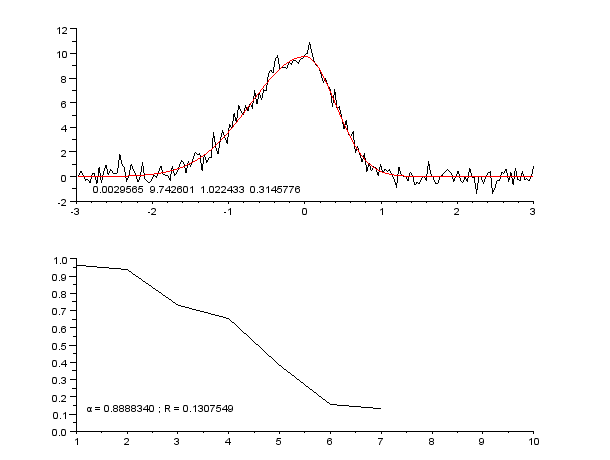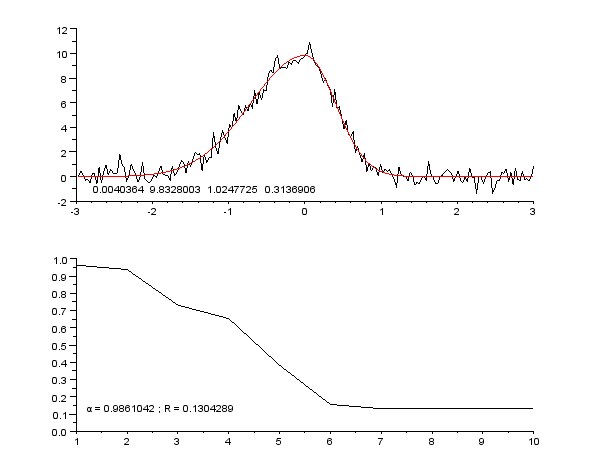
Но вот предсказывать то надо будущее! В качестве данных вне выборки были взяты следующие 9 дней после данных внутри выборки. На данных вне выборки среднеквадратичная ошибка составила 32 пункта, что конечно неприемлемо для реальной торговли, но говорит о том, что в направлении нейросетей можно работать дальше - игра должна стоить свеч.

Результатом нашей работы является многослойная гибридная нейронная сеть, которая способна прогнозировать абсолютные значения цен на небольшой будущее. Она кардинально отличается своей архитектурой и целями от однослойной нейронной сети, представленной господином Решетовым в своей статье http://articles.mql4.com/ru/articles/1447 и реализованной в качестве эксперта https://www.mql5.com/ru/code/10289.
Нам удалось получить более-менее сносный прогноз по самим котировкам, хотя специалисты в области нейронных сетей настоятельно не рекомендуют делать это. Полученной нейросетью можно полюбоваться при нажатии кнопки Structure. Обученную нейросеть можно взять в прикрепленых файлах neuro.zip .

Заключение
Нейронные сети являются очень мощным инструментом для работы на финансовых рынках, но для освоения этого этой технологии нужно потратить времени уж точно не меньше, чем на освоение технического анализа.
Плюсом нейросетей является объективность при принятии решения, а минусом – то, что решение принимает фактически черный ящик.
Основные проблемы, возникающие при работе с этой технологией – правильная предобработка данных, этот этап играет решающую роль для прогнозирования данных и очень многие безуспешные попытки работы с нейросетями связаны именно с этим этапом.
Для того, чтобы хорошо освоить нейросети нужно очень много экспериментировать – но игра стоит свеч. Если институциональные инвесторы используют этот инструмент, то и рядовые трейдеры тоже могут попытаться добиться успеха именно с помощью обученных нейросетей, ведь на вход сети можно подавать все – от индикаторов и цен до сигналов фундаментального анализа.
Литература
1. Нейрокомпьютинг и его применение в науке и бизнесе. А. Ежов, С. Шумский. 1998 г
www.mql5.com
нейросети для Форекс / Tradehow
В то время, как большинство трейдеров бьется в поисках Грааля, совершенствуя механические торговые системы и графические методы анализа, небольшая, но прогрессивная часть занимается разработкой нейронных сетей в трейдинге и их продвижением. Что же такое нейронная сеть, и каковы перспективы ее использования на рынках ценных бумаг?
Что такое искусственная нейронная сеть?

Принципиальная схема нейросети.
Искусственная нейросеть построена по принципу биологических нейронных сетей, то есть, она копирует организацию нервных клеток живого организма и состоит из искусственных нейронов. Она представляет собой математическую модель и ее воплощение в аппаратном и программном обеспечении для осуществления сложных логических вычислений.
Интересно! Нейроны искусственной нейронной сети иногда называют сумматорами. Нейрон получает информацию, обрабатывает ее с помощью простых арифметических действий и передает ее дальше.
Простая нейросеть состоит из трех нейронов:
- входного;
- скрытого;
- выходного.
Эта последовательность называется перцептроном. Если нейросеть сложная, то нейроны в ней могут образовывать слои (обычно не более трех). Ключевой способностью нейронной сети является способность к обучению.
Основные задачи, решаемые с помощью нейросетей:
- классификация – распределение данных по параметрам;
- прогнозирование – например, курса валют исходя из имеющихся данных;
- распознавание образов;
Наиболее успешно нейронные технологии применяются для распознавания образов.
Для справки! Голосовые команды и фраза «окей, Гугл» — тоже нейросети.
Классификация нейросетей
Нейросети классифицируются по количеству слоев нейронов:
- однослойные — с одним слоем;
- многослойные — с несколькими скрытыми слоями.
Также по направлению движения информации они могут быть следующих видов:
- прямого распространения – информация двигается только в одном направлении;
- рекуррентные – с обратными связями;
Возможности рекуррентных сетей пока слабо изучены, так как анализировать их сложно. Потенциал у них очень велик.
Нейронные сети в трейдинге
Нейротехнологии пока не нашли себе широкого применения в трейдинге. Тем не менее, они имеют потенциал, так как позволяют обнаруживать в исходных данных любые повторяющиеся модели. Также в качестве источников данных для анализа можно использовать не только котировки, но, при необходимости, и любую информацию, вплоть до фаз луны и календаря индейцев Майя. При этом, можно комбинировать как технические данные, так и фундаментальные.
Важным преимуществом нейросетей в трейдинге перед механическими торговыми системами является возможность обрабатывать гигантские объемы информации, способность обучаться и адаптироваться к изменениям рынка.
Например, механические советники и торговые роботы периодически нужно перенастраивать, иначе они начинают приносить убытки. Существуют трендовые роботы и роботы хорошо работающие в боковике. Нейронная сеть способна подстраиваться под изменения рынка самостоятельно, без участия человека.
Программное обеспечение для создания нейросетей в трейдинге
Уже довольно давно на рынке присутствуют достаточно мощные пакеты и программные комплексы, позволяющие как проектировать нейронные сети для Форекс самостоятельно, так и включающие в себя готовые решения для торговли.
| ExelNeuralPacckage | Пакет, разработанный российскими специалистами расширяющий возможности MS Exel в области нейротехнологий. |
| Nero Brainmaker | Несложная программа для проектирования сетей с большим количеством слоев. |
| NeuroLab | Приложение для Wealth-Lab. |
| NeuralWorks | Семейство продуктов для разработки сетей. |
| NeuroShell | Продукты для решения широкого ряда задач, в том числе и в трейдинге. |
| Trading Solutions | Специализированная программа для трейдеров, позволяющая им создавать и отлаживать нейронные сети. |
| Statistica | Продукты компании StatSoft для статистического анализа, в том числе, с применением нейросетей. |
Для Форекс-трейдеров существует возможность писать роботов и советников на языках MQL4 и MQL5. Для работы в этом направлении есть соответствующие библиотеки. Также можно использовать пакет NeuroSolutions который позволяет не только создавать нейронные сети, но и подключаться к MetaTrader.
Недостатки нейросетей, работающих на Форекс

К сожалению, на сегодняшний день нейронные сети в трейдинге показывают противоречивые результаты. Это связано со следующими причинами:
- Нейросети являются разновидностью статистического анализа и поэтому им свойственны все проблемы и болезни статистических методов: успешный анализ исторических данных не гарантирует успеха в будущем – это утверждение в полной мере справедливо и для нейросетей.
- По мере усложнения сети, количество вычислений растет по экспоненте.
- Нейронные сети работают по принципу черного ящика: загружая в сеть данные и получая результат, трейдер не понимает принципов, на основании которых она принимает решение, значит он не склонен доверять ей свои деньги, тем более, на таком рынке, как Форекс.
Для решения этой проблемы, разработчики нейросетей предусматривают вывод данных в виде математических формул. Но для того чтобы в них разобраться, нужно обладать серьезными знаниями в области математики.
В краткосрочной торговле, и, в частности, на Форекс, нейросети показывают слабую эффективность, тем самым подтверждая утверждение нобелевского лауреата Юджина Фама о хаотическом характере изменения цены и невозможности предсказаний в краткосрочном плане. Однако они могут быть полезны для анализа долгосрочных процессов и выработки инвестиционных прогнозов, а также при анализе инвестиционных рисков.
Уже сейчас банки и инвестиционные компании активно применяют нейротехнологии. Возможность обрабатывать большие массивы и способность к обучению, позволяют нейронным сетям на Форекс идентифицировать более сложные паттерны, чем это возможно с помощью механических и графических методов.
Не исключено, что нейросетям в будущем будет вполне по силам самостоятельно осуществлять поиск неэффективностей рынка – закономерностей, которые позволяют трейдеру зарабатывать. В настоящее время, использование на рынке стратегий, основанных на нейротехнологиях, возможно с применением грамотного риск-менеджмента и управления капиталом.
tradehow.ru
Воскрешение нейросетей для трейдинга | Jivas.org
В последнее время все чаще можно услышать о нейросетях и машинном обучении. Например, Microsoft, а затем Google заявили о внедрении нейросетей в свои переводчики. Естественно на таком фоне, популярность нейросетей снова возрастает, что конечно же не может игнорировать трейдерское сообщество.
В этом нет ничего странного, для трейдеров это новая, а вернее забытая старая надежда, которая была популярна в докризисные годы. Такие программы как neuroshell, neurosolutions были очень популярны в среде трейдеров. Однако, не стоит обольщаться на тему использования нейросетей для торговли на рынке форекс или бирже – звучит заманчиво, наукообразно, затягивает, но в целом бесполезно и вот почему.
Что нужно искать на рынке с помощью нейросетей?
Использование любого математического аппарата для прогнозирования временных рядов подразумевает, что входные данные содержат некую информацию, с помощью которой можно построить прогноз с минимальными ошибками. Многие люди наивно полагают, что прошлое содержит информацию о будущем, но для рынка это не так. Вы можете самостоятельно провести исследования автокорреляции любых рыночных данных с самими собой или поискать статистически значимые взаимосвязи между различными рыночными данными и ценами, взятыми со сдвигом в будущее. Вы должны сами убедиться и принять однозначный вывод о НЕ прогнозируемости рынка, любым способом, основанном на ценовых, индикаторных данных.
Это не значит, что нейросети не выполняют возложенную на них функцию. Можно прогнозировать и распознавать образы, паттерны, но для того, чтобы стабильно зарабатывать на рынке, нужны стабильно существующие паттерны, на которых можно сделать прибыль. Только есть одна проблема – не существует стабильных технических паттернов.
Деньги на рынке можно сделать только тогда, когда между прошлыми данными и будущими существует связь, например, за неким событием с высокой вероятностью следует другое и трейдер может получить прибыль, делая ставку на это «другое» событие. При этом прибыли от успешно сработавших ситуаций должно быть больше, чем убытков от не сработавших ситуаций. Иначе какой смысл искать паттерны или ситуации, которые не ведут к прибыли? А знаете, что? Именно такие паттерны и ищут с помощью нейросетей, которые приводят к убыткам. То есть прежде, чем тренировать нейросеть, нужно уже иметь прибыльную идею или паттерн.
Кстати, многие пропагандируют идею о том, что можно натравить нейросеть на данные, а она, что-то найдёт сама – это называется подгонкой. Нейросеть сгенерирует красивые картинки на истории, но поскольку паттерна в реальности не существует и это подгонка, то результат в реальности сразу будет убыточным. Откуда я все это знаю? Я занимался нейросетями до 2008 года, у нас даже были некоторые успехи по распознанию паттернов. Но поскольку стабильно существующих прибыльных паттернов на длительной истории просто нет, мы отказались от нейросетей.
Когда уместно использовать нейросети?
Когда между данными прошлого и будущего существуют корреляции, достаточные для извлечения прибыли. На высоких горизонтах и в фундаментальных данных такие связи существуют! Простой пример — предсказание вероятности рецессий, крахов и т.д. Однако, все эти модели основаны на статистике и регрессионном анализе, то есть для построения такой модели, не нужны нейросети, они попросту избыточны.
На самом деле, авторы-новоделы по нейросетям понятия не имеют, что получают на выходе. Как правило это красивые аппроксимации временных рядов, хотя на самом деле просто подглядывание в будущее или прогноз методом «завтра будет тоже, что и сегодня» или неустойчивый паттерн без потенциала к прибыли.
Как же можно использовать нейросети?
Для классификации сложных ситуаций нейросети подходят очень хорошо. Если сами ситуации, которые классифицируют потенциально убыточны, то сеть определит паттерны верно, но вы просто на этом не сможете заработать.
Условные примеры.
- Возьмём «условный флаг». Если флаг имеет положительную статистику на протяжении длительного времени, то можно научить нейросеть находить любые флаги. Но если этот паттерн убыточен, то какой в этом смысл? Вы, наверное, думаете, что мой то паттерн – прибыльный! Ну это чаще не так, если посчитать статистику, то вы узнаете, как на самом деле. Если вы используете прибыльный паттерн/ситуацию – поздравляю, но если у вас нет даже статистики, то на что расчёт?
- Более сложная ситуация: выход положительного NFP + цена в определённой области канала, а волатильность такая-то. Статистически при таком раскладе рынок делает достаточное для прибыли движение. Если ли смысл использовать нейросеть? Возможно да, особенно если определение такого паттерна имеет в основе нечёткую логику и весовые коэффициенты.
Что является прогнозируемым и предсказуемым?
Только то, что имеет или трендовость или цикличность, потому, что это автоматически означает наличие связи между прошлым и будущим. Погода прогнозируема с некой небольшой погрешностью, потому, что есть сезонность / цикличность так же есть некая глобальная трендовость температур и есть трендовость внутри сезонности. Именно поэтому погода прогнозируема, так как она очень стационарна и действительно повторяется, то есть по сути прошлые наблюдения содержат информацию о будущем.
Именно поэтому все, кто в теме, торгуют долгосрочные тренды или Моментум, как правило это инвесторы, а умные спекулянты торгуют сезонность/цикличность товарных спредов.
Почему другие зависимости не имеют значения для рынка?
Почему другие зависимости не имеют значения для рынка, например, некая условная вероятность? Потому, что вы просто не сможете извлечь прибыль. Ну представьте себе, что в сентябре месяце у вас есть вероятность сбора урожая равной ¼. Это значит, что только в один год из четырех вы сможете собрать яблоки, причём вы не знаете в какой именно год. Стоит ли на этом выстраивать бизнес — НЕТ! Аналогия уместна и на рынке – да, действительно существует некие условности и некие ситуации в которых если наступает событие, то вслед за ним с некой слегка отличной от ½ вероятностью наступает желаемое движение или событие на рынке. На этом просто нельзя заработать денег.
Выводы:
- Нейросети хорошо классифицируют ситуации, паттерны.
- Если нет связи между прошлым и будущим, то ни нейросети, ни человек не могут прогнозировать будущее.
- Связь между прошлым и будущим – это или наличие тренда в ряде данных или наличие цикличности в ряде данных.
- Если в вашем наборе данных нет паттернов или они не значимы, то их нет смысла использовать. Есть ли у вас исторические симуляции, например, как вот эти, за 10-20 лет? Кстати, вы можете открыть статистики фондов и посмотреть, что у множества именно подобные результаты. Может стоит использовать то, что работает и делать как фонды, то есть — инвестировать?
- Ну, а если вера ваша сильна и по вашему скромному мнению рынок определяется кукловодами, то просто посчитайте статистику за несколько лет, форекс головного мозга излечивается именно так.
Успешного заработка с помощью рынка!
jivas.org
Разрабатываем простую модель глубокого обучения для прогнозирования цен акций с помощью TensorFlow
Эксперт в области data science и руководитель компании STATWORX Себастьян Хайнц опубликовал на Medium руководство по созданию модели глубокого обучения для прогнозирования цен акций на бирже с использованием фреймворка TensorFlow. Мы подготовили адаптированную версию этого полезного материала.
Автор разместил итоговый Python-скрипт и сжатый датасет в своем репозитории на GitHub.
Импорт и подготовка данных
Хайнц экспортировал биржевые данных в csv-файл. Его датасет содержал n = 41266 минут данных, охватывающих торги 500 акциями в период с апреля по август 2017, также в него вошла информация по цене индекса S&P 500. # Импорт данных data = pd.read_csv('data_stocks.csv') # Сброс переменной date data = data.drop(['DATE'], 1) # Размерность датасета n = data.shape[0] p = data.shape[1] # Формирование данных в numpy-массив data = data.values Так выглядит временной ряд индекса S&P, построенный с помощью pyplot.plot(data['SP500']):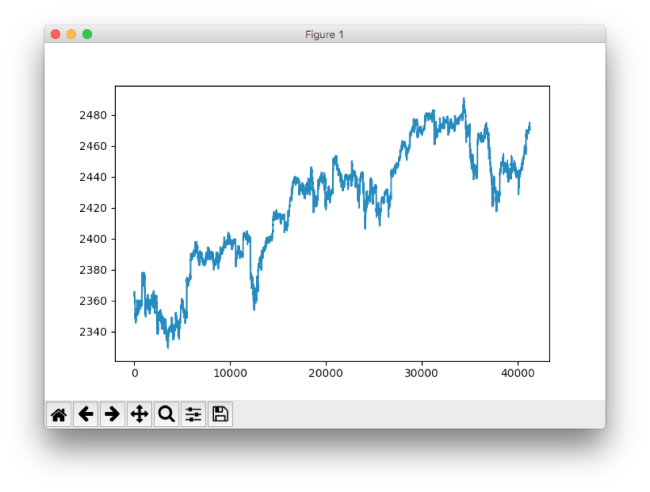
Интересный момент: поскольку конечная цель заключается в «предсказании» значения индекса в ближайшем будущем, его значение сдвигается на одну минуту вперед.
Подготовка данных для тестирования и обучения
Набор данных был разбит на два — одна часть для тестирования, а вторая для обучения. При этом, данные для обучения составили 80% от всего их объема и охватили период с апреля до приблизительно конца июля 2017 года, данные для тестирования оканчивались августом 2017 года. # Данные для тестирования и обучения train_start = 0 train_end = int(np.floor(0.8*n)) test_start = train_end test_end = n data_train = data[np.arange(train_start, train_end), :] data_test = data[np.arange(test_start, test_end), :] Существует множество подходов к кросс-валидации временных рядов, от генерации прогнозов с или без перенастройкой модели (refitting) до более сложных концептов вроде bootstrap-ресемплирования временных рядов. В последнем случае данные разбиваются на повторяющиеся выборки начиная с начала сезонной декомпозиции временного ряда — это позволяет симулировать выборки, которые следуют тому же сезонному паттерну, что и оригинальный временной ряд, но не полностью копируют его значения.Масштабирование данных
Большинство архитектур нейронных сетей используют масштабирование входных данных (а иногда и выходных). Причина в том, что большинство функций активации нейронов вроде сигмовидной или гиперболической касательной (tanx) определены на интервалах [-1, 1] или [0, 1], соответственно. В настоящее время, наиболее часто используются активации выпрямленной линейной единицей (ReLU). Хайнц решил масштабировать входные данные и цели, использовав для этой цели MinMaxScaler в Python:# Масштабирование данных from sklearn.preprocessing import MinMaxScaler scaler = MinMaxScaler() scaler.fit(data_train) data_train = scaler.transform(data_train) data_test = scaler.transform(data_test) # Построение X и y X_train = data_train[:, 1:] y_train = data_train[:, 0] X_test = data_test[:, 1:] y_test = data_test[:, 0] Примечание: следует быть внимательным при выборе части данных и времени для масштабирования. Распространенная ошибка здесь — масштабировать весь датасет до его разбиения на тестовые и обучающие данные. Это ошибка, поскольку масштабирование запускает подсчет статистики, то есть минимумов/максимумов переменных. При осуществлении прогнозирования временных рядов в реальной жизни, на момент их генерации у вас не может быть информации из будущих наблюдений. Поэтому подсчет статистики должен производиться на тренировочных данных, а затем полученный результат применяться к тестовым данным. Брать для генерирования предсказаний информацию «из будущего» (то есть из тестовой выборки), то модель будет выдавать прогнозы с «системной предвзятостью» (bias).Введение в TensorFlow
TensorFlow — отличный продукт, в настоящий момент это самый популярный фреймворк для решения задач машинного обучения и создания нейронных сетей. Бэкенд продукта основан на C++, однако для управления обычно используется Python (также существует замечательная библиотека TensorFlow для R). TensorFlow использует концепцию графического представления вычислительных задач. Такой подход позволяет пользователям определять математические операции в качестве элементов графов данных, переменных и операторов. Поскольку нейронные сети, по сути, и являются графами данных и математических операций, TensorFlow отлично подходит для работы с ними и машинного обучения. В примере ниже представлен граф, который решает задачу сложения двух чисел:
На рисунке выше представлены два числа, которые нужно сложить. Они хранятся в переменных a и b. Значения путешествуют по графу и попадают в узел, представленный квадратом, где и происходит сложение. Результат операции записывается в другую переменную c. Использованные переменные можно рассматривать как плейсхолдеры. Любые числа, попадающие в a и b, складываются, а результат записывается в c.
Именно так и работает TensorFlow — пользователь определяет абстрактное представление модели (нейронной сети) через плейсхолдеры и переменные. После этого первые наполняются реальными данными и происходят вычисления. Тестовый пример выше описывается следующим кодом в TensorFlow:
# Импорт TensorFlow import tensorflow as tf # Определение a и b в качестве плейсхолдеров a = tf.placeholder(dtype=tf.int8) b = tf.placeholder(dtype=tf.int8) # Определение сложения c = tf.add(a, b) # Инициализация графа graph = tf.Session() # Запуск графа graph.run(c, feed_dict={a: 5, b: 4}) После импорта библиотеки TensorFlow с помощью tf.placeholder() определяются два плейсхолдера. Они соответствуют двум голубым кругам в левой части изображения выше. После этого, с помощью tf.add() определяется операция сложения. Результат операции — это c = 9. При настроенных плейсхолдерах граф может быть исполнен при любых целочисленных значениях a и b. Понятно, что этот пример крайне прост, а нейронные сети в реальной жизни куда сложнее, но он позволяет понять принципы работы фреймворка.Плейсхолдеры
Как сказано выше, все начинается с плейсхолдеров. Для того, чтобы реализовать модель, нужно два таких элемента: X содержит входные данные для сети (цены акций всех элементов S&P 500 в момент времени T = t) и выходные данные Y (значение индекса S&P 500 в момент времени T = t + 1).Форма плейсхолдеров соответствует [None, n_stocks], где [None] означает, что входные данные представлены в виде двумерной матрицы, а выходные данные — одномерного вектора. Важно понимать, какая форма входных и выходных данных нужна нейросети и соответственным образом их организовать.
# Плейсхолдер X = tf.placeholder(dtype=tf.float32, shape=[None, n_stocks]) Y = tf.placeholder(dtype=tf.float32, shape=[None]) Аргумент None означает, что в этой точке мы еще не знаем число наблюдений, которые пройдут через граф нейросети во время каждого запуска, поэтому он остается гибким. Позднее будет определена переменная batch_size, которая контролирует количество наблюдений в ходе обучающего «прогона».Переменные
Помимо плейсхолдеров, во вселенной TensorFlow есть и другой важнейший элемент — это переменные. Если плейсхолдеры используются для хранения входных и целевых данных в графе, то переменные служат гибкими контейнерами внутри графа. Им позволено изменяться в процессе выполнения графа. Веса и смещения представлены переменными для того, чтобы облегчить адаптацию во время обучения. Переменные необходимо инициализировать перед началом обучения.Модель состоит из четырех скрытых уровней. Первый содержит 1024 нейрона, что чуть более чем в два раза превышает объем входных данных. Последующие скрытые уровни всегда в два раза меньше предыдущего — они объединяют 512, 256 и 128 нейронов. Снижение числа нейронов на каждом уровне сжимает информацию, которую сеть обработала на предыдущих уровнях. Существуют и другие архитектуры и конфигурации нейронов, но в этом руководстве используется именно такая модель:
# Параметры архитектуры модели n_stocks = 500 n_neurons_1 = 1024 n_neurons_2 = 512 n_neurons_3 = 256 n_neurons_4 = 128 n_target = 1 # Уровень 1: Переменные для скрытых весов и смещений W_hidden_1 = tf.Variable(weight_initializer([n_stocks, n_neurons_1])) bias_hidden_1 = tf.Variable(bias_initializer([n_neurons_1])) # Уровень 2: Переменные для скрытых весов и смещений W_hidden_2 = tf.Variable(weight_initializer([n_neurons_1, n_neurons_2])) bias_hidden_2 = tf.Variable(bias_initializer([n_neurons_2])) # Уровень 3: Переменные для скрытых весов и смещений W_hidden_3 = tf.Variable(weight_initializer([n_neurons_2, n_neurons_3])) bias_hidden_3 = tf.Variable(bias_initializer([n_neurons_3])) # Уровень 4: Переменные для скрытых весов и смещений W_hidden_4 = tf.Variable(weight_initializer([n_neurons_3, n_neurons_4])) bias_hidden_4 = tf.Variable(bias_initializer([n_neurons_4])) # Уровень выходных данных: Переменные для скрытых весов и смещений W_out = tf.Variable(weight_initializer([n_neurons_4, n_target])) bias_out = tf.Variable(bias_initializer([n_target])) Важно понимать, какие размеры переменных требуются для разных уровней. Практическое правило мультиуровневых перцептронов гласит, что размер предыдущего уровня — это первый размер текущего уровня для матриц весов. Звучит сложно, но суть в том, что каждый уровень передает свой вывод в качестве ввода следующему уровню. Размеры смещений равняются второму размеру матрицы весов текущего уровня, что соответствует число нейронов в уровне.Разработка архитектуры сети
После определения требуемых весов и смещений переменных, сетевой топологии, необходимо определить архитектуру сети. Таким образом, плейсхолдеры (данные) и переменные (веса и смещения) нужно объединить в систему последовательных матричных умножений. Скрытые уровни сети трансформируются функциями активации. Эти функции — важные элементы сетевой инфраструктуры, поскольку они привносят в систему нелинейность. Существуют десятки функций активации, и одна из самых распространенных — выпрямленная линейная единица (rectified linear unit, ReLU). В данном руководстве используется именно она:# Скрытый уровень hidden_1 = tf.nn.relu(tf.add(tf.matmul(X, W_hidden_1), bias_hidden_1)) hidden_2 = tf.nn.relu(tf.add(tf.matmul(hidden_1, W_hidden_2), bias_hidden_2)) hidden_3 = tf.nn.relu(tf.add(tf.matmul(hidden_2, W_hidden_3), bias_hidden_3)) hidden_4 = tf.nn.relu(tf.add(tf.matmul(hidden_3, W_hidden_4), bias_hidden_4)) # Выходной уровень (должен быть транспонирован) out = tf.transpose(tf.add(tf.matmul(hidden_4, W_out), bias_out)) Представленное ниже изображение иллюстрирует архитектуру сети. Модель состоит из трех главных блоков. Уровень входных данных, скрытые уровни и выходной уровень. Такая инфраструктура называется упреждающей сетью (feedforward network). Это означает что куски данных продвигаются по структуре строго слева-направо. При других реализациях, например, в случае рекуррентных нейронных сетей, данные могут перетекать внутри сети в разные стороны.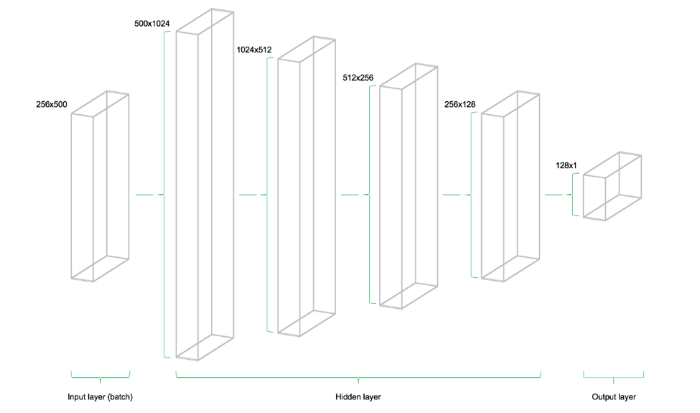
Функция стоимости
Функция стоимости сети используется для генерации оценки отклонения между прогнозами сети и реальными результатами наблюдений в ходе обучения. Для решения проблем с регрессией используют функцию средней квадратичной ошибки (mean squared error, MSE). Данная функция вычисляет среднее квадратичное отклонение между предсказаниями и целями, но вообще для подсчета отклонения между может быть использована любая дифференцируемая функция.# Функция стоимости mse = tf.reduce_mean(tf.squared_difference(out, Y)) При этом, MSE отображает конкретные сущности, которые полезны для решения общей проблемы оптимизации.Оптимизатор
Оптимизатор берет на себя необходимые вычисления, требующиеся для адаптации весов и переменных отклонений нейросети в ходе обучения. Эти вычисления ведут к подсчетам так называемых градиентов, которые обозначают направление необходимого изменения отклонений и весов для минимизации функции стоимости. Разработка стабильного и быстрого оптимизатора — одна из основных задач создателей нейронных сетей.# Оптимизатор opt = tf.train.AdamOptimizer().minimize(mse) В данном случае используется один из наиболее распространенных оптимизаторов в сфере машинного обучения Adam Optimizer. Adam — это аббревиатура для фразы “Adaptive Moment Estimation” (адаптивная оценка моментов), он представляет собой нечто среднее между двумя другими популярными оптимизаторами AdaGrad и RMSPropИнициализаторы
Инициализаторы используются для инициализации переменных перед стартом обучения. Поскольку нейронные сети обучаются с помощью численных техник оптимизации, начальная точки проблемы оптимизации — это один из важнейших факторов на пути поиска хорошего решения. В TensorFlow существуют различные инициализаторы, каждый из которых использует собственный подход. В данном руководстве использован tf.variance_scaling_initializer(), который реализует одну из стандартных стратегий инициализации.# Инициализаторы sigma = 1 weight_initializer = tf.variance_scaling_initializer(mode="fan_avg", distribution="uniform", scale=sigma) bias_initializer = tf.zeros_initializer() Примечание: в TensorFlow можно определять несколько функций инициализации для различных переменных внутри графа. Однако в большинстве случаев достаточно унифицированной инициализации.Настройка нейросети
После определения плейсхолдеров, переменных, инициализаторов, функций стоимости и оптимизаторов, модель необходимо обучить. Обычно для этого используется подход мини-партий (minibatch training). В ходе такого обучения из набора данных для обучения отбираются случайные семплы данных размера n = batch_size и загружаются в нейросеть. Набор данных для обучения делится на n / batch_size кусков, которые затем последовательно отправляются в сеть. В этот момент в игру вступают плейсхолдеры X и Y. Они хранят входные и целевые данные и отправляют их в нейросеть.Семплированные данные X проходят по сети до достижения выходного уровня. Затем TensorFlow сравнивает сгенерированные моделью прогнозы с реально наблюдаемыми целями Y в текущем «прогоне». После этого TensorFlow выполняет этап оптимизации и обновляет параметры сети, после обновления весов и отклонений, процесс повторяется снова для нового куска данных. Процедура повторяется до того момента, пока все «нарезанные» куски данных не будут отправлены в нейросеть. Полный цикл такой обработки называется «эпохой».
Обучение сети останавливается по достижению максимального числа эпох или при срабатывании другого определенного заранее критерия остановки.
# Создание сессии net = tf.Session() # Запуск инициализатора net.run(tf.global_variables_initializer()) # Настройка интерактивного графика plt.ion() fig = plt.figure() ax1 = fig.add_subplot(111) line1, = ax1.plot(y_test) line2, = ax1.plot(y_test*0.5) plt.show() # Количество эпох и размер куска данных epochs = 10 batch_size = 256 for e in range(epochs): # Перемешивание данных для обучения shuffle_indices = np.random.permutation(np.arange(len(y_train))) X_train = X_train[shuffle_indices] y_train = y_train[shuffle_indices] # Обучение мини-партией for i in range(0, len(y_train) // batch_size): start = i * batch_size batch_x = X_train[start:start + batch_size] batch_y = y_train[start:start + batch_size] # Run optimizer with batch net.run(opt, feed_dict={X: batch_x, Y: batch_y}) # Показать прогресс if np.mod(i, 5) == 0: # Prediction pred = net.run(out, feed_dict={X: X_test}) line2.set_ydata(pred) plt.title('Epoch ' + str(e) + ', Batch ' + str(i)) file_name = 'img/epoch_' + str(e) + '_batch_' + str(i) + '.jpg' plt.savefig(file_name) plt.pause(0.01) # Вывести финальную фукнцию MSE после обучения mse_final = net.run(mse, feed_dict={X: X_test, Y: y_test}) print(mse_final) В ходе обучения оценивались предсказания, сгенерированные сетью на тестовом наборе, затем осуществлялась визуализация. Кроме того, изображения выгружались на диск и позднее из них создавалась видео-анимация процесса обучения:Как видно, нейросеть быстро адаптируется к базовой форме временного ряда и продолжает искать наилучшие паттерны данных. После прошествия 10 эпох мы получаем результаты, очень близкие к тестовым данным. Финальное значение функции MSE составляет 0,00078 (очень маленькое значение из-за того, что цели масштабированы). Средняя абсолютная процентная погрешность прогноза на тестовом наборе равняется 5,31% — очень хороший результат. Важно понимать, что это лишь совпадение с тестовыми, а не реальными данными.
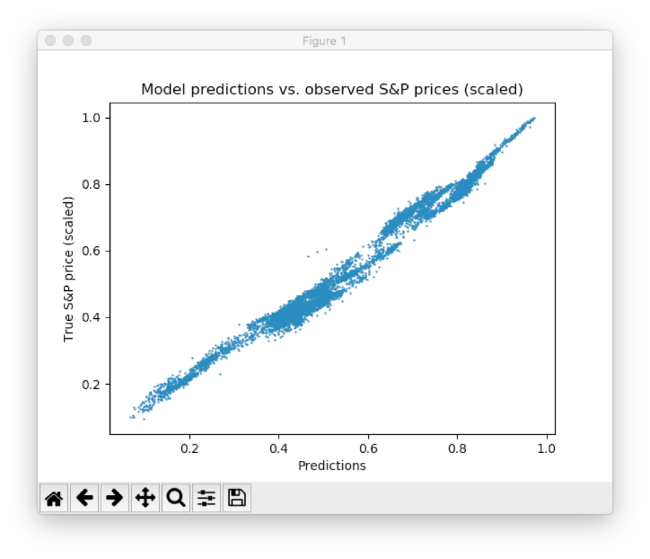
График рассеяния между предсказанными и реальными ценами S&P
Этот результат можно еще улучшить множеством способов от проработки уровней и нейронов, до выбора иных схем инициализации и активации. Кроме того, могут быть использованы различные типы моделей глубокого обучения, вроде рекуррентных нейросетей — это также может приводить к лучшим результатам.
Другие материалы по теме финансов и фондового рынка от ITI Capital:
habr.com








